在数字营销时代,用户购后评论数据蕴含着巨大的商业价值。本文通过实操案例,展示了从数据收集、标签体系构建到洞察提炼的全过程,深入探讨了如何利用人工智能(AI)技术对这些数据进行深度分析,以洞察用户的真实需求和市场趋势。

从海量用户评价中剖析出市场需求,无异于沙里淘金。
一方面在于用户评价很多时候是不痛不痒的「中评」,看不出来顾客到底想表达什么?
另一方面在于「海量」,评价太多了,根本看不完,如果用传统的python等工具分析,工作量又非常大。
更不用说:
1. “标准统一吗?”——主观判断的困扰: 不同的人对同一条评论的理解可能千差万别。今天A同学打的标签,明天B同学可能就不认同。这种“尺子”不统一的问题,导致分析结果的准确性和可信度大打折扣。
2. “挖得深吗?”——表面现象的迷雾: 传统的关键词统计或许能告诉你用户在讨论什么,但很难揭示这些讨论背后的深层原因、情感倾向以及不同用户群体的差异化需求。我们往往只能停留在“用户提到了XX”的层面,难以形成真正驱动决策的洞察。
幸好,AI来了。
但即使在AI时代,很多人做用户评论分析的方法就是直接把采集到的用户评论一股脑扔进AI里,让AI自己去分析得出结论。基本上这样的结论,要么是数据幻觉严重,要么是时好时坏,跟买彩票一样。
那么,如果你想稳定得到有效的用户评论洞察分析报告,就需要有一套方法框架,然后在这个基础上搭建一个AI工作流。今天我们就来做这样的实践。
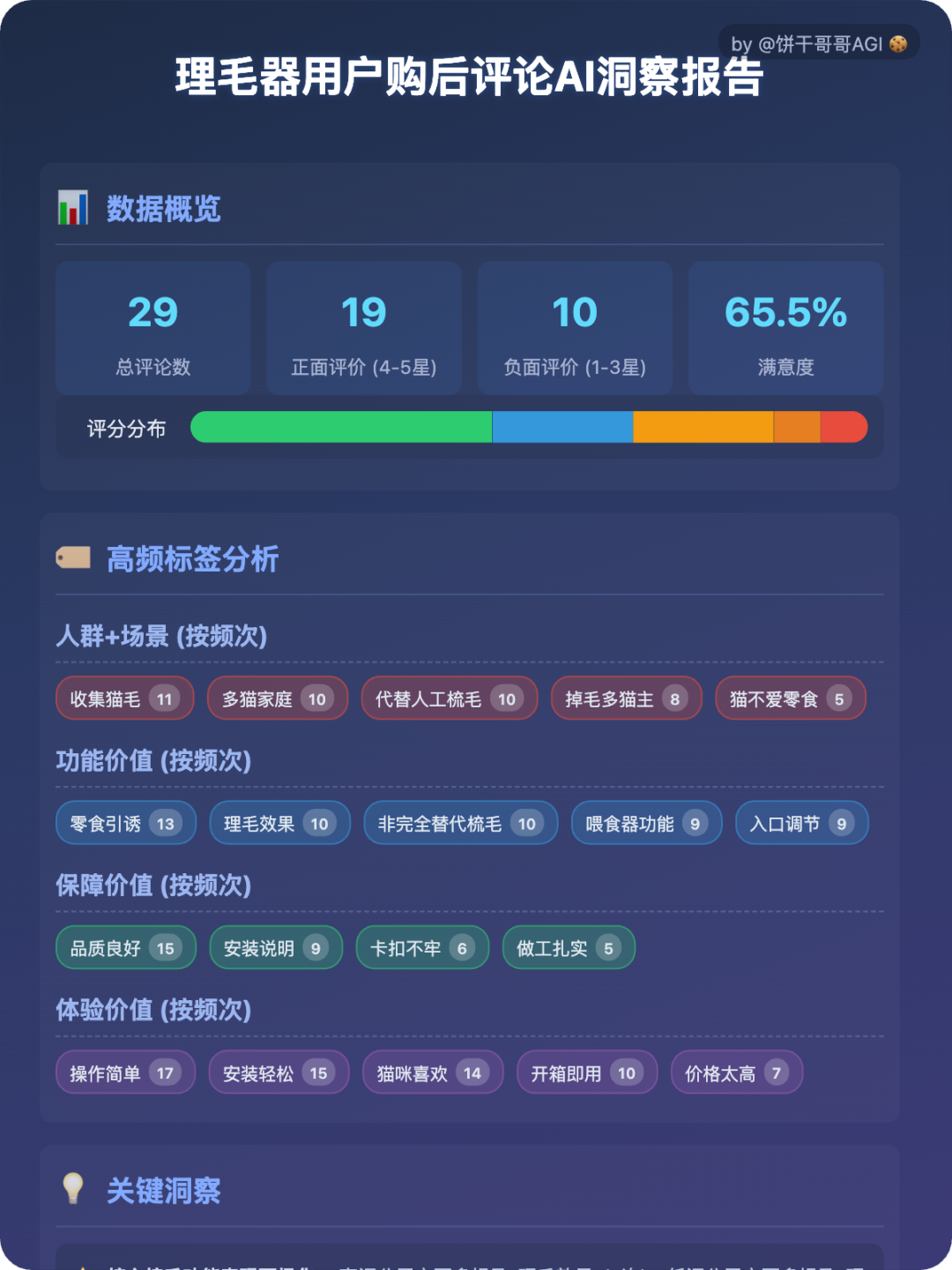
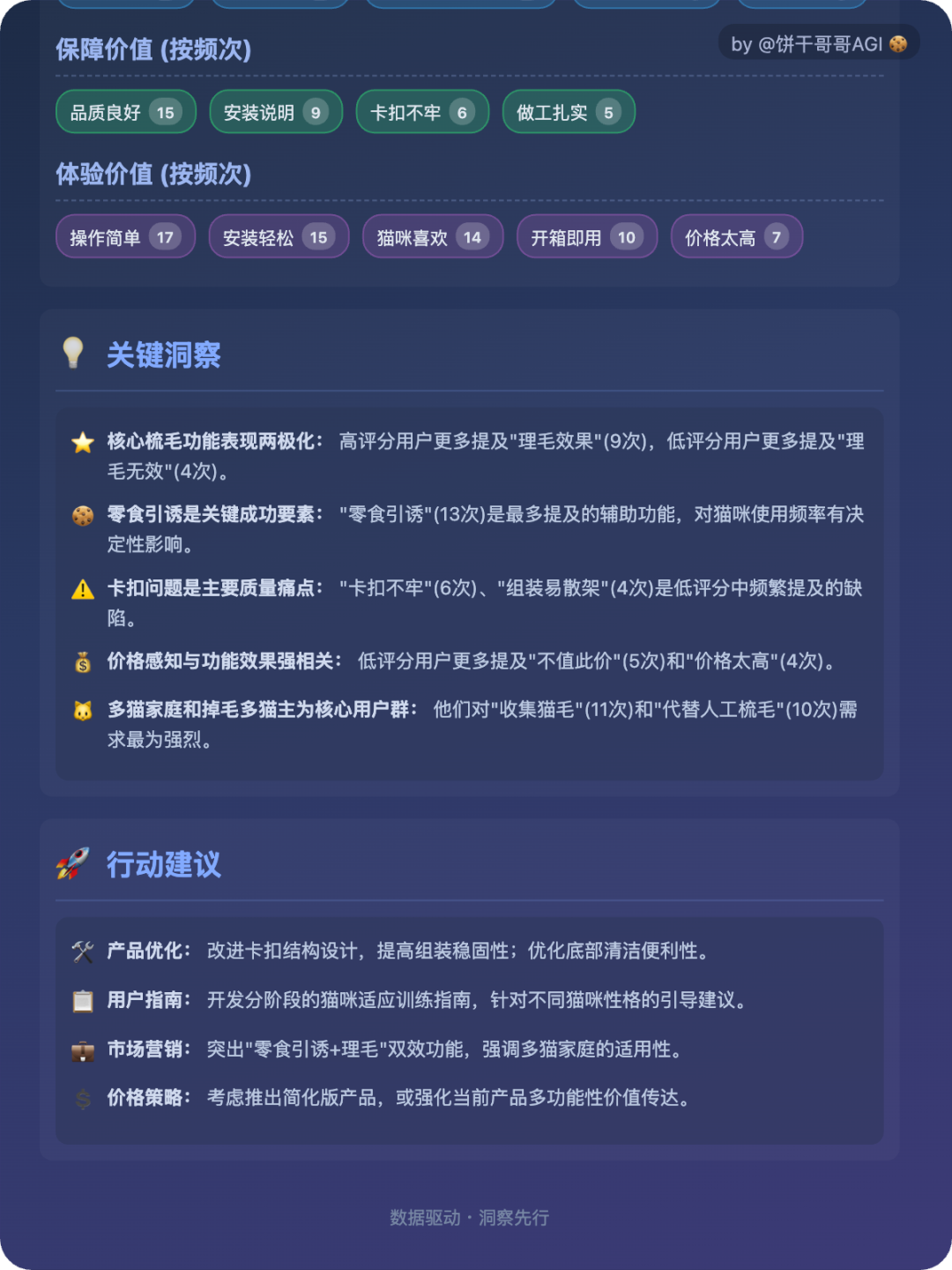
下图就是此次实操做的用户购后评论AI洞察报告:
[fancyad id=”45″]
它不仅能做正确的数据统计,还能实现评论打标后的频次与交叉分析,最终得出关键洞察与行动建议。
(此次分析是基于业务场景来做的,报告结果也得到了业务的认可,具体可见文末。)
在正式开始之前,我们做分析还是要带入真实的业务场景。
假设我们是卖下面这块自动理毛器的。
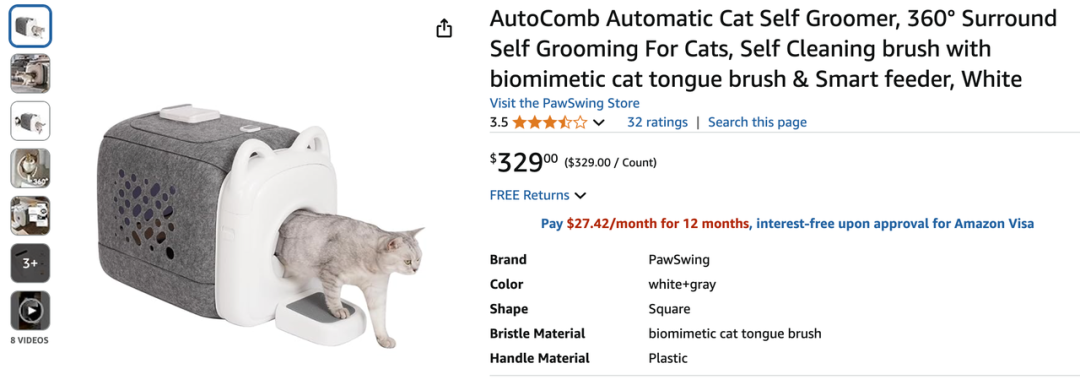
产品地址:https://www.amazon.com/PawSwing-AutoComb-Automatic-Surround-biomimetic/dp/B0DMSVNTC1/ref=cm_cr_arp_d_product_top?ie=UTF8
可以看到,亚马逊上的评论内容都很丰富,很适合拿来做评论洞察分析。
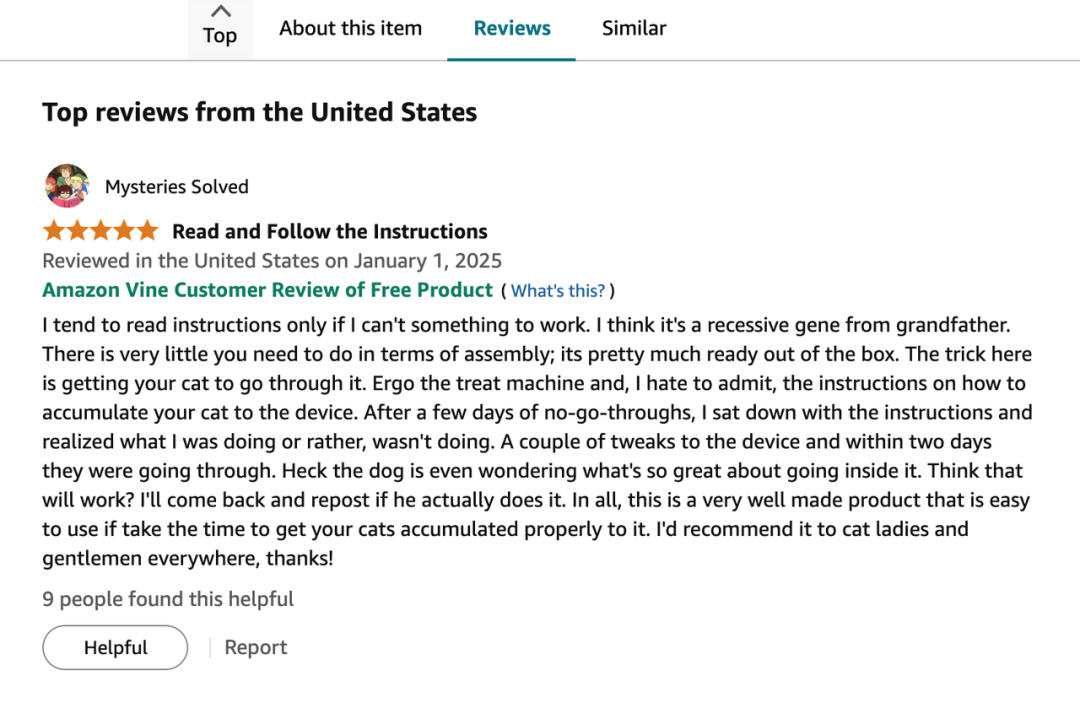 用户购后评论
用户购后评论
洞察分析方法论
在做任何分析之前,必须有「章法」也就是方法论、理论框架。
以下就是我们做用户购后评论洞察分析的方法论,图片是总结。
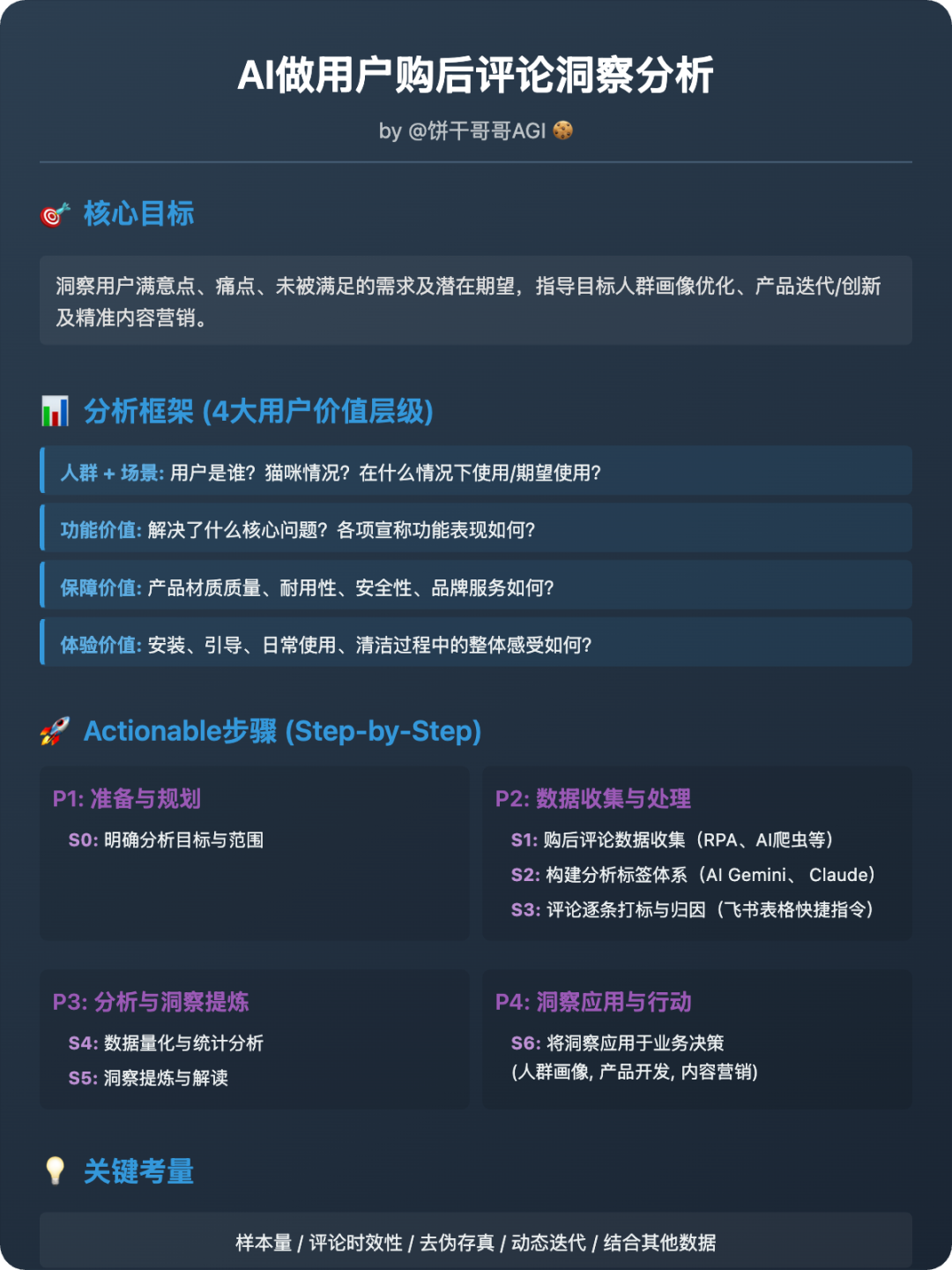
往下,可以看到这个方法论是怎么把一大块一大块的用户评论,逐渐拆解成多个标签,然后再基于标签做交叉洞察分析,得出我们想要的业务建议的。
核心目标
通过深度分析用户购买后留下的真实评论,洞察用户在实际使用中的满意点、痛点、未被满足的需求以及潜在期望,从而指导目标人群画像优化、产品迭代/创新及精准内容营销。
分析框架
基于产品的4大用户价值层级:
1. 人群 + 场景 (Crowd + Scenario): 用户是谁?他们的猫是什么样的?他们在什么情况下使用/期望使用这款猫咪自助理毛器?
2. 功能价值 (Functional Value): 这款自助理毛器解决了用户的什么核心问题(如减少猫毛、猫咪自娱自乐)?各项宣称功能(如模仿猫舌、收集猫毛、智能喂食器)表现如何?
3. 保障价值 (Assurance Value): 产品的材质质量、耐用性、安全性(对猫友好)、品牌服务(如说明书、配件)如何?
4. 体验价值 (Experience Value): 用户(和猫)在安装、引导、日常使用、清洁过程中的整体感受如何?(便捷性、猫咪接受度、产品设计美观度、噪音等)
落地步骤
阶段一:准备与规划
Step 0: 明确分析目标与范围
目标:本次分析是为了优化AutoComb自助理毛器的用户体验,并为下一代产品寻找创新点,同时提炼更精准的营销沟通信息。
产品范围:明确分析亚马逊上 “AutoComb Automatic Cat Self Groomer, 360° Surround Self Grooming For Cats…” (白色款) 的评论。
时间范围:选取产品上市以来至近一个月的所有评论。
平台范围:亚马逊美国站。
阶段二:数据收集与处理
Step 1:购后评论数据收集
渠道:从亚马逊该产品页面的“Customer reviews”模块获取数据。
工具:可使用亚马逊后台评论导出、第三方评论分析工具或浏览器插件。
内容:收集评论文本、星级评分、Verified Purchase标识、评论图片/视频、评论日期、用户名(用于识别是否多猫家庭的线索)等。
Step 2:构建分析标签体系核心原则
围绕4大用户价值层级,结合AutoComb产品特性,设计细化标签。
标签示例 (以AutoComb为例):
1)人群+场景:
- 养猫人群特征:长毛猫主、多猫家庭、猫咪体型(大/小)、猫咪性格(胆小/好奇)、猫咪年龄(幼猫/成年猫/老年猫)、猫主人经验(新手/老手)、对猫毛困扰程度(高/中/低)。
- 使用场景/期望:减少家中浮毛、猫咪自娱自乐、替代人工梳毛、猫咪躲避空间/小窝、猫咪行为训练(结合零食机)、作为猫咖/救助站用品。
2)功能价值:
- 核心理毛功能:理毛效果(去浮毛量)、模仿猫舌设计感受、自清洁刷毛、360°环绕理毛。
- 智能喂食功能:零食机引诱效果、零食机易用性、零食机充电/续航、零食机记录功能(QR码)。
- 猫毛收集功能:猫毛收集便利性、猫毛毡化元素(趣味性)。
- 适应性:适应不同体型猫咪、入口大小调节。
- 供电方式:无需电力(理毛部分)。
3)保障价值:
- 产品材质/质量:材料质感(如毛毡、塑料)、结构稳固性、耐用性(如按扣、刷毛)、配件质量(如充电线)、产品有无异味。
- 品牌服务/支持:安装说明清晰度(如超大说明书)、配件提供(如额外刷头)、客服响应。
- 猫咪安全性:材质对猫安全、无锐利边角、刷毛温和度。
4)体验价值:
- 安装体验:安装便捷度(如按扣设计)、是否需要工具、安装耗时。
- 猫咪接受度/使用体验:猫咪初次反应、猫咪适应过程/时长、猫咪是否喜欢/主动使用、猫咪在内部停留时长/行为(睡觉/观察)、猫咪是否会玩耍/互动。
- 主人操作体验:入口大小调节便捷性、零食机操作便捷性、清洁便利性(特别是底部)、产品移动便携性(重量vs便携)。
- 感官体验:产品外观设计、产品体积/占空间、运行噪音(若有)、零食机屏幕可读性。
- 价格感知:性价比、价格是否过高。
- 情感价值:是否减轻主人负担、是否增进人宠互动(反向,如评论中提到的“disconnects you from bonding time”)、趣味性(如猫毛毡化)、推荐意愿。
情感倾向标签:为每个细分标签点再打上正面、负面、中性/建议的情感倾向。
Step 3:评论逐条打标与归因方法
可以借助飞书多维表格的「快捷指令」来完成。
示例评论:
“Great quality and works well to help groom my very long haired Siberian cat. He’s quite big and he still has no issues making himself comfortable in it. It’s also his hidy-hole… He loves getting treats in it as well… this does help with the amount of cat hair that we usually have to clean up.”
打标:
- 保障价值 -> 产品材质/质量 -> 正面
- 功能价值 -> 理毛效果(去浮毛量) -> 正面
- 人群+场景 -> 长毛猫主 -> 中性
- 人群+场景 -> 猫咪体型(大) -> 中性
- 体验价值 -> 猫咪接受度/使用体验(舒适/藏身处) -> 正面
- 功能价值 -> 智能喂食功能(零食机引诱效果) -> 正面
阶段三:数据分析与洞察提炼
Step 4:数据量化与统计分析
频次统计:统计“安装便捷度(正面)”提及20次,“安装便捷度(负面,如按扣难扣)”提及5次。
交叉分析:
- 人群 x 需求点:分析多猫家庭评论中,对零食机引诱效果的评价是正面居多还是负面居多。
- 场景 x 需求点:分析期望减少家中浮毛的用户,对理毛效果的满意度如何。
- 痛点与亮点:“猫咪适应过程(需要耐心引导)”可能是常见中性/建议点,“零食机引诱”是亮点,“价格过高”是常见痛点。
趋势分析 (可选):分析早期评论和近期评论中,对“安装便捷性”的反馈是否有变化(可能与产品批次或说明书更新有关)。
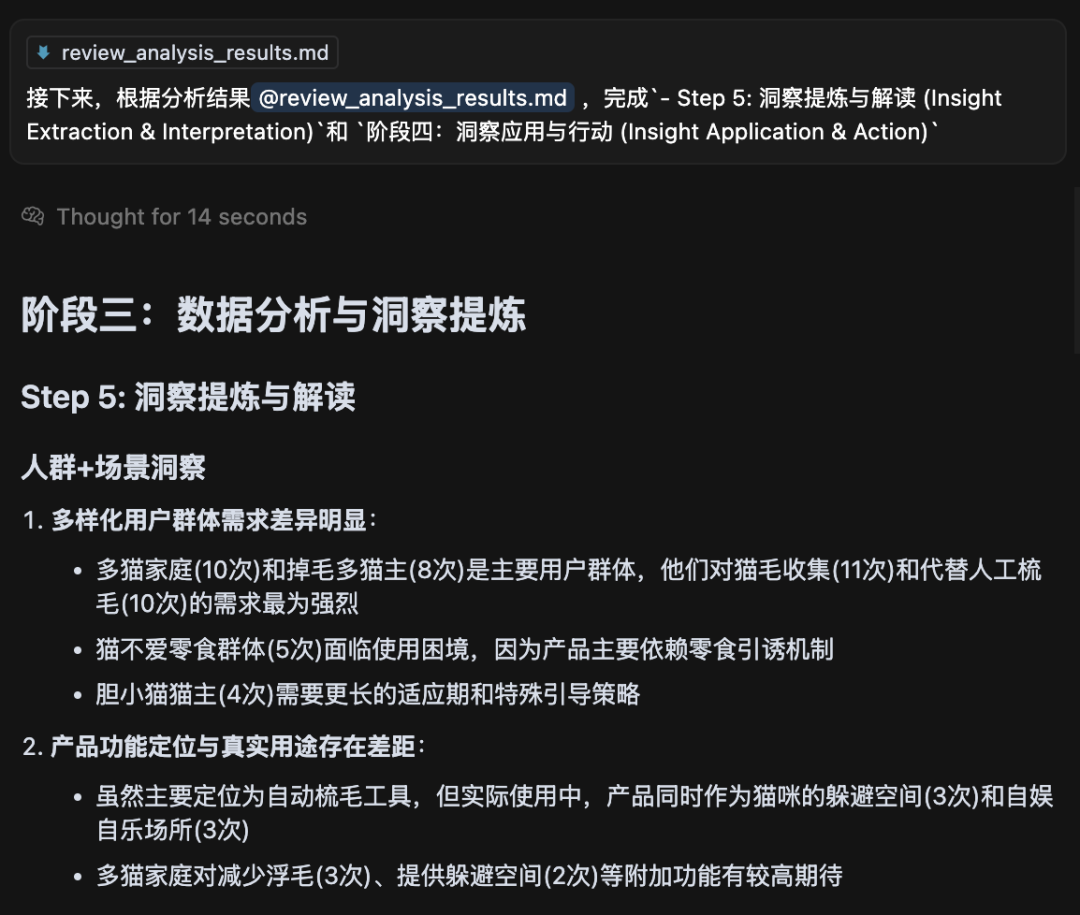
Step 5:洞察提炼与解读
围绕4大价值层级进行总结:
- 人群+场景洞察:购后评论显示,产品对长毛猫和多猫家庭有一定吸引力,但猫咪性格(胆小)是接受产品的一大挑战。部分用户将其视为猫咪的私密空间而非纯粹的理毛工具。
- 功能价值洞察:零食机引诱功能被普遍认为是引导猫咪使用的有效手段。理毛效果方面,用户反馈不一,部分认为有帮助减少浮毛,但不能完全替代人工刷毛。入口大小调节功能受到好评。
- 保障价值洞察:用户对产品使用的材料质感(如毛毡的稳固性)评价不一,部分认为“well built”,部分认为“flimsy”。安装说明清晰度有提及,但按扣的安装体验是负面反馈点之一。
- 体验价值洞察:安装过程(特别是按扣)是一些用户的痛点。猫咪适应过程需要主人耐心和正确引导,遵循说明书很重要。产品体积较大、底部不易清洁是体验上的不足。价格感知普遍偏高。
识别关键问题与机会:
- 核心痛点:猫咪接受度与训练成本、部分组件安装困难、底部清洁不便、性价比感知。
- 独特优势:零食引诱与理毛结合的创新概念、猫咪的“私密小窝”属性。
- 未满足需求:更简易的安装方式、更易清洁的底座材质、针对不同性格猫咪的更细化引导方案、更具竞争力的价格。
阶段四:洞察应用与行动
Step 6:将洞察应用于业务决策
1)目标人群画像
优化/生成:
输入:Step 5中用户常说的“hidy-hole”、“treat dispenser is key”、“takes time to acclimate”、“helps with cat hair”、“hilarious cat hair felting”。
输出:
- 优化画像:更强调“愿意投入时间训练猫咪的爱猫人士”,而非“追求一劳永逸的懒人猫主”。
- 细分画像:“科技养宠尝鲜者”,他们对新奇产品感兴趣,愿意为“智能化”、“自动化”付费,但对实际效果和易用性有较高期待。
- 画像描述应包含:养宠情况(猫品种、数量、性格),养宠痛点(猫毛、猫咪独自在家的娱乐),对新产品的态度,对价格的敏感度,以及对产品功能、体验的期望(如易于引导猫咪使用、真实有效的理毛效果)。
2)产品开发:
老品优化:
输入:
Step 5中关于“按扣安装困难”、“底部毛毡不易清洁”、“零食机屏幕难读”、“部分猫咪对刷头不适或理毛效果不佳”的反馈。
输出:
- 功能价值:研究更有效的刷毛材质和结构,优化入口调节机制以适应更多猫咪。
- 保障价值:改进按扣设计或采用其他更稳固便捷的连接方式,考虑使用更耐用的毛毡或提供可更换的毛毡部件。
- 体验价值:底座改为可拆卸清洗的防水材质,增大零食机屏幕或优化显示,提供更详细的猫咪引导视频教程。
新品机会挖掘:
输入:用户对“更低价格但保留核心引诱和轻度理毛功能”的潜在需求,或对“模块化设计,可单独购买喂食模块或理毛模块”的兴趣。
输出:
概念1: “AutoComb Lite”,简化版,专注于零食引诱和基础理毛,价格更亲民。
概念2: “智能猫咪互动站”,强化娱乐和喂食功能,理毛作为辅助,增加App互动和远程控制。
3)内容营销:
输入:Step 5中关于“长毛猫主”、“多猫家庭主人”、“对猫咪行为训练有耐心的主人”的洞察,以及他们对“减少浮毛”、“猫咪娱乐与奖励”、“产品耐用性”的关注。
输出:
- 卖点提炼与沟通:强调“零食引诱,让猫咪爱上梳毛”、“不仅是理毛器,更是猫咪的私享空间”、“有效减少家中飞毛”。
- 痛点共鸣与解决方案呈现:制作“如何快速让猫咪适应AutoComb”的教程视频/图文,强调遵循说明书的重要性。针对“价格高”的顾虑,可以突出其多功能性(理毛+喂食+娱乐+猫窝)和长期使用的价值。
- 场景化内容:“长毛猫换毛季的救星:AutoComb实测”、“多猫家庭和谐养宠,从共享AutoComb开始”。
- 用户证言收集:筛选那些成功引导猫咪使用并看到效果的正面评价,特别是包含猫咪可爱使用视频/图片的评论。
- FAQ与客服脚本优化:针对“安装困难”、“猫不进去怎么办”、“清洁问题”等高频疑问,提供标准答案和解决方案。
关键考量
- 样本量:确保分析的评论数量足够代表整体用户,避免因样本过小导致结论偏差。
- 评论时效性:优先分析较新的评论,更能反映当前用户的心声。
- 去伪存真:注意识别和过滤无效评论、恶意差评或刷好评。
- 动态迭代:用户需求和市场环境是变化的,购后评论洞察应定期进行,标签体系和分析重点也可能需要随之调整。
- 结合其他数据:将评论洞察与其他数据(如销售数据、客服反馈、调研数据、行业报告)结合,进行多维度验证,使结论更可靠。
AI评论分析实践
OK,看了理论之后,我们就对用户评论洞察有了概念,但如果让你直接上手去做,就会发现有很多卡点。不着急,我们来逐个解决。
(这里跳过数据采集部分,可以参考上一期我介绍的AI爬虫,也可以用RPA去采集。)
从问题说起
做用户评论的关键在于给评论打多个不同维度的标签,也称为「打标」,具体执行上,我们可以把评论逐个发给AI,让AI返回打标结果给我们。
但问题来了。
每次发评论给ai都是独立的,也就是说ai每次打标签的标准是不统一的,包括标签的名字也不一样,这个怎么解决?
理论上说,应该先设计一套标签体系,再让ai在这个标签范围内去挑选打标签,但每次产品都不同,或者情况都不同,怎么才能快速用ai建立好标签体系呢?而且还是一个符合业务落地的标签体系。
这里就特别需要AI的能力:
先把一部分评论扔给AI(如果量少的话直接全部扔进去都行,需要长上下文的王者支持,例如Gemini、KIMI等),然后再人工调整。
生成标签体系
下面是我这次用到的提示词,有几个关键地方:
1. 理论学习,要把我们的理论框架扔给AI,它才能跟我们同频
2. 标签设计原则,标签不是随便打的,至少要符合MECE原则
3. 输出示例与结果格式,最终我们得到的标签体系是要扔给AI继续做下一步的,所以最好拿到JSON的格式
# AI提示词:构建用户评论分析标签体系
## 您的任务:
您是一位经验丰富的产品分析专家和自然语言处理专家。您的任务是基于我提供的一批用户购后评论文本,为该产品构建一个结构化的、多层级的分析标签体系。这个标签体系将用于后续对每条评论进行细致的分类和打标,以便深入洞察用户需求和反馈。## 核心理论知识(请先学习并理解)
1. 用户价值层级模型: 我们将从用户的角度出发,将他们对产品的关注点和评价归纳到以下四个核心价值层级。您的标签设计需要围绕这些层级展开:
* 人群与场景 (Crowd & Scenario): 描述的是“谁”在“什么情况下”使用或提及产品。这包括用户的身份特征、所处环境、使用产品的具体情境或期望达成的目标。
* 功能价值 (FunctionalValue): 指产品为了解决用户的核心问题所提供的具体功能、性能表现以及操作特性。
* 保障价值 (AssuranceValue): 涉及产品的质量、耐用性、安全性、可靠性,以及品牌提供的售前、售中、售后服务和支持。
* 体验价值 (ExperienceValue): 涵盖用户在与产品交互的整个生命周期中的主观感受,包括感官体验(外观、声音、气味等)、操作便捷性、情感连接等。2. 标签设计原则:
* 层级性: 标签体系应具有清晰的层级结构(一级标签、二级标签、三级标签)。
* 覆盖性: 能够尽可能全面地覆盖评论中用户提及的主要议题。
* 互斥性(理想状态): 同一级下的标签应尽可能互斥,避免语义重叠过多。
* 简洁性: 每个标签的名称应简洁明了,尽量不超过5个汉字。
* 客观性: 标签本身不应包含情感倾向(如“效果好”、“质量差”),仅客观描述讨论的主题(如“清洁效果”、“产品材质”)。情感分析将在后续打标步骤中独立进行。
* 可扩展性: 体系应具备一定的灵活性,方便未来根据新的评论内容进行补充和调整。标签体系层级结构定义:
* 一级标签 (Level1Tag): 必须是以下四个固定维度之一:
1.`人群场景`
2.`功能价值`
3.`保障价值`
4.`体验价值`* 二级标签 (Level2Tag): 是对一级标签的进一步细分,代表了该价值层级下的主要关注领域。
* 示例(针对一款“猫咪自助理毛器”产品,仅作启发,您需要根据提供的实际评论生成):
* 一级标签:`人群场景`
* 二级标签:`养宠特征` (如猫品种、数量、年龄、性格)
* 二级标签:`使用期望` (如减少浮毛、猫咪娱乐)
* 一级标签:`功能价值`
* 二级标签:`理毛功能` (如理毛效果、刷毛设计)
* 二级标签:`喂食功能` (如零食引诱、机器操作)
* 二级标签:`猫毛收集`
* 一级标签:`保障价值`
* 二级标签:`产品质量` (如材质、耐用性)
* 二级标签:`品牌支持` (如安装说明、配件)
* 二级标签:`猫咪安全`
* 一级标签:`体验价值`
* 二级标签:`安装体验`
* 二级标签:`猫咪反应` (如接受度、使用行为)
* 二级标签:`主人操作` (如清洁、调节)
* 二级标签:`感官感受` (如外观、体积、噪音)
* 二级标签:`价格感知`* 三级标签 (Level3Tag): 是对二级标签的具体化,代表了用户评论中实际讨论到的、更细致的主题点。这是您需要根据提供的评论文本重点设计的部分。
* 示例(续上例,针对“猫咪自助理毛器”):
* 一级标签:`功能价值`
* 二级标签:`理毛功能`
* 三级标签:`理毛效果`
* 三级标签:`刷毛材质`
* 三级标签:`入口调节`
* 二级标签:`喂食功能`
* 三级标签:`零食引诱`
* 三级标签:`喂食机操作`
* 三级标签:`喂食机续航`
* 一级标签:`体验价值`
* 二级标签:`安装体验`
* 三级标签:`安装便捷`
* 三级标签:`安装耗时`
* 三级标签:`按扣设计`
* 二级标签:`猫咪反应`
* 三级标签:`猫咪喜欢`
* 三级标签:`猫咪害怕`
* 三级标签:`适应过程`您的具体操作指令:
1. 仔细阅读并分析我稍后提供的一批用户购后评论文本。
2. 基于上述理论知识、层级结构定义和设计原则,为这批评论所讨论的产品生成一个三级标签体系。
3. 一级标签和二级标签的类别和名称,您可以参考我给出的示例进行扩展或调整,使其更贴合实际评论内容,但一级标签必须是固定的四个维度。
4. 三级标签是您创造性的核心,需要您从评论中提炼用户实际讨论的具体议题点,并用简洁的词语命名。
5. 确保每个三级标签都归属于一个明确的二级标签和一级标签。
6. 输出格式要求:请以结构化的JSON格式输出您设计的标签体系。 这样便于我直接将其用于后续的AI打标任务。格式如下:“`json
[
{
“level_1_tag”: “人群场景”,
“level_2_tags”: [
{
“level_2_tag_name”: “养宠特征”, // (示例二级标签,请您根据文本生成)
“level_3_tags”: [
“猫咪品种”, // (示例三级标签,请您根据文本生成)
“猫咪数量”,
“猫咪年龄”
]
},
{
“level_2_tag_name”: “使用期望”, // (示例二级标签)
“level_3_tags”: [
“减少浮毛”,
“猫咪娱乐”,
“替代人工”
]
}
// … 更多该一级标签下的二级标签及其三级标签
]
},
{
“level_1_tag”: “功能价值”,
“level_2_tags”: [
{
“level_2_tag_name”: “核心功能A”, // (示例二级标签,请替换为具体功能,如 理毛功能)
“level_3_tags”: [
“功能A效果”, // (示例三级标签,如 理毛效果)
“功能A设计”, // (示例三级标签,如 刷毛设计)
“功能A参数” // (示例三级标签,如 入口大小)
]
},
{
“level_2_tag_name”: “辅助功能B”, // (示例二级标签,如 喂食功能)
“level_3_tags”: [
“功能B效果”, // (示例三级标签,如 零食引诱)
“功能B操作” // (示例三级标签,如 喂食机操作)
]
}
// … 更多该一级标签下的二级标签及其三级标签
]
},
{
“level_1_tag”: “保障价值”,
“level_2_tags”: [
// … 请您根据文本设计二级和三级标签
]
},
{
“level_1_tag”: “体验价值”,
“level_2_tags”: [
// … 请您根据文本设计二级和三级标签
]
}
]
“`请确认您已理解以上所有要求。在我提供用户评论文本后,请开始您的分析和标签体系构建工作。
逐个评论打标签
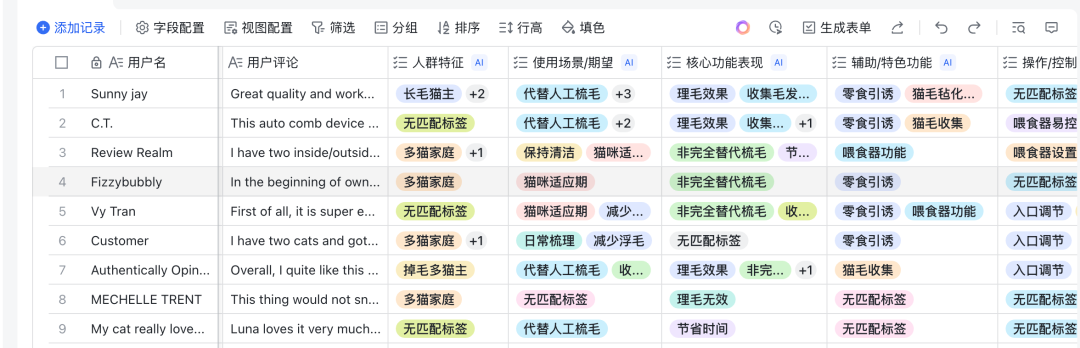
得到标签体系后,我们就要逐条评论给AI打标。
注意这里打标,不是说给几个标签就完事了,是要让AI针对不同的维度分别打标,这样的标签才丰富,后续才能聚合做分析。效果长这样:
这么复杂的工程该不会有人一条一条发给AI吧????
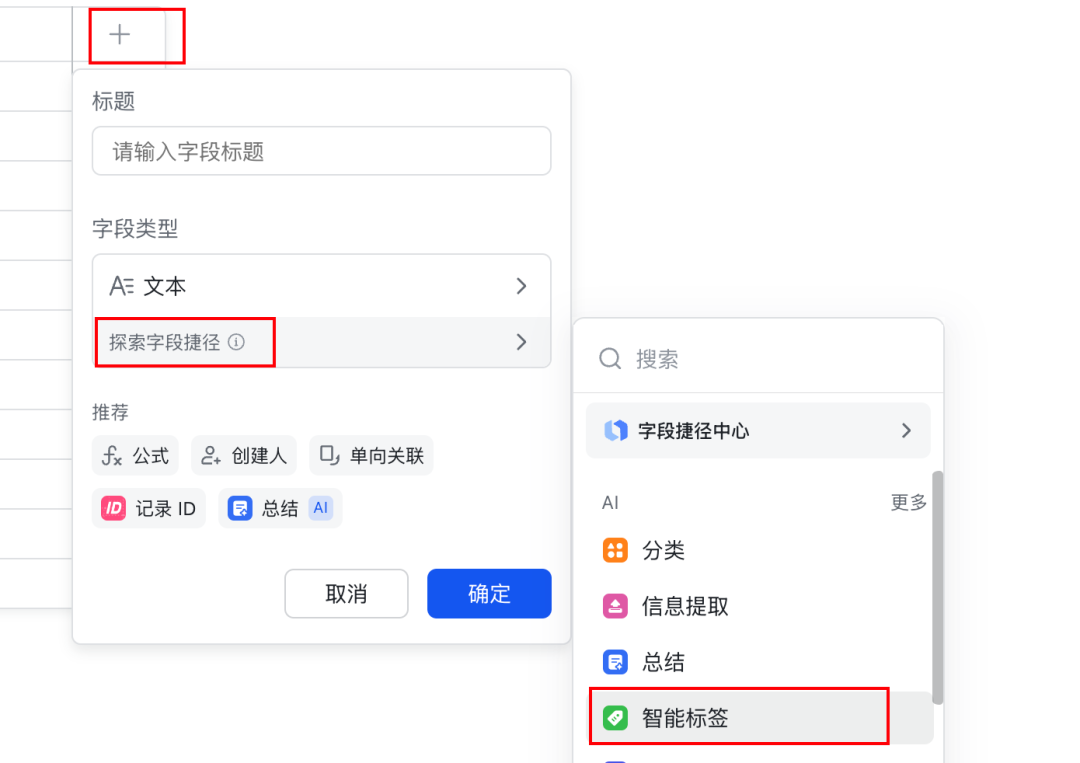
这里我们可以借助飞书多维表格里的「字段捷径」来实现。
先把数据上传到飞书多维表格里,然后针对每个「二级标签」来新建字段,选择「字段捷径」里的「智能标签」
它能用Deepseek 来对内容进行打标。
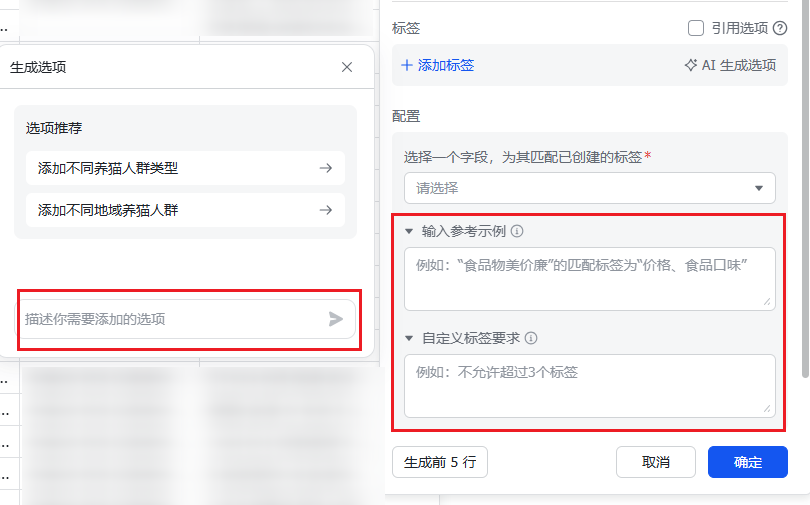
新建字段后,又有新的问题了,每个二级标签下这么多的三级标签,难道要一个一个填吗?
这里每个字段的参考示例、标签要求怎么填?不填效果不好
这里我们又要借助AI的能力来帮我们完成。
提示词:
接下来,下一步,需要你生成用于我逐条评论发给AI打标签的提示词。同样需要给示例,我需要用如图的飞书多维表格来处理,所以还需要给我对应的每个部分的示例和标签要求,按以下标签体系的二级标签,一个二级标签对应:一个输入参考示例、一个自定义标签要求、一个添加的选项描述(就是介绍这个列是什么,然后列出所有的三级标签)
以下是标签体系:
“`
把前面生成好的标签体系放进来
“`
这样我们就生成了每个字段下需要的选项和示例、标签要求。
一级标签:人群与场景
A. 二级标签:人群特征
– 添加的选项描述 (列描述及可选标签):
描述:识别评论中提及的与猫主人或猫咪本身相关的身份、特征或所属群体。
可选三级标签:长毛猫主, 多猫家庭, 大型猫主, 短毛猫主, 幼猫猫主, 老猫猫主, 胆小猫主, 掉毛多猫主, 猫不爱零食, 猫咖/救助站– 输入参考示例 (Few-shot Learning Example):
评论文本:”Great quality and works well to help groom my very long haired Siberian cat. He’s quite big…”
对应标签:长毛猫主, 大型猫主– 自定义标签要求 (Constraints for AI):
如果评论中明确提到猫的品种、毛发长度、体型、年龄、数量或主人身份(如救助站),请选择对应标签。一条评论可能对应多个“人群特征”标签。B. 二级标签:使用场景/期望
– 添加的选项描述 (列描述及可选标签):
描述:识别评论中用户描述的实际使用产品的情境、环境,或他们购买产品时期望达成的目的或应用场景。
可选三级标签:减少浮毛, 猫咪自娱, 代替人工梳毛, 保持清洁, 日常梳理, 猫咪适应期, 提供躲避空间, 收集猫毛– 输入参考示例 (Few-shot Learning Example):
评论文本:”I have two inside/outside cats and thought this would be great to help keep them cleaner… It’s also his hidy-hole…”
对应标签:保持清洁, 提供躲避空间– 自定义标签要求 (Constraints for AI):
关注用户提及购买产品的主要原因或期望解决的问题。如果提到猫咪在里面的特定行为(如躲藏),也请选择。…后面太长了就忽略了,都是一样的结果。
接下来要做的就是逐个字段去新建、填入,例如:
1. 新建「人群特征」列
2. 在标签的位置选择「AI生成选项」
3. 然后把标签描述扔到左边,生成后点「采纳」
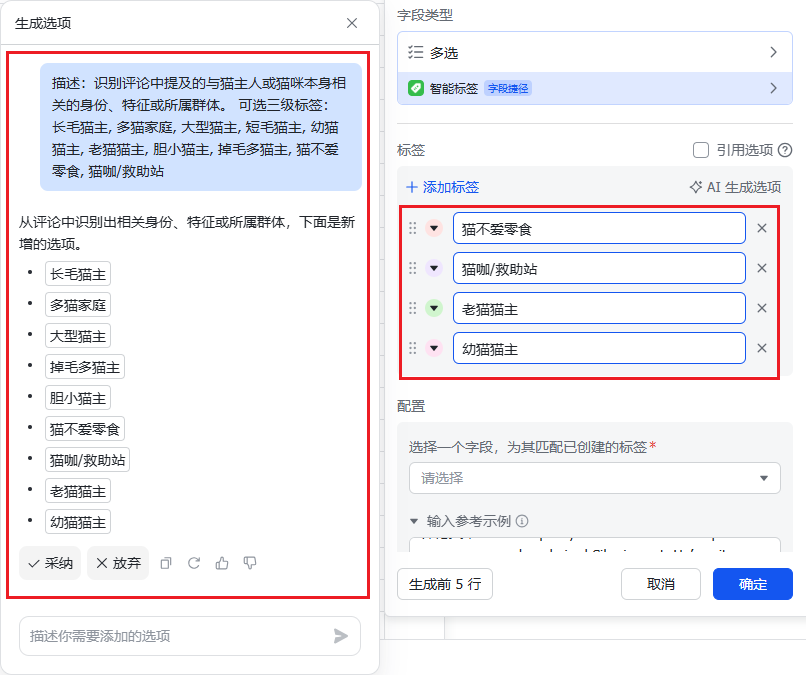
4. 把参考示例、标签要求填进去下图对应位置
5. 选择字段那里,选择「用户评论」也就是你放评论的那列
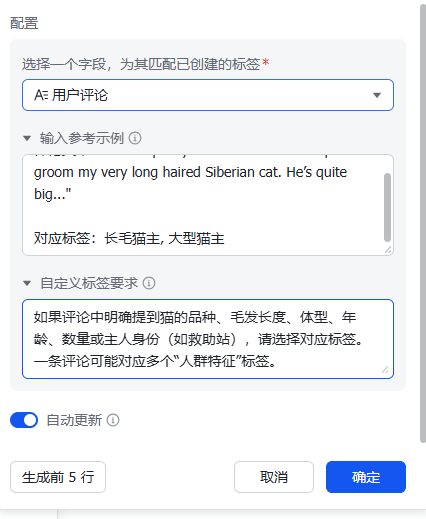
点确定后,它就会开始每行去打标签
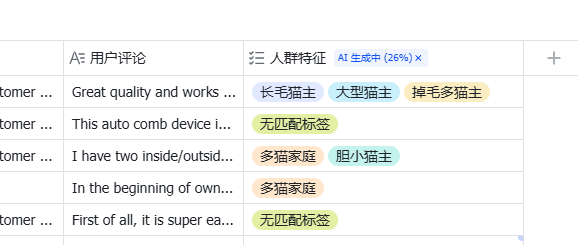
最终就得到了理论框架里的4个维度下的12个二级标签里的多个三级标签。
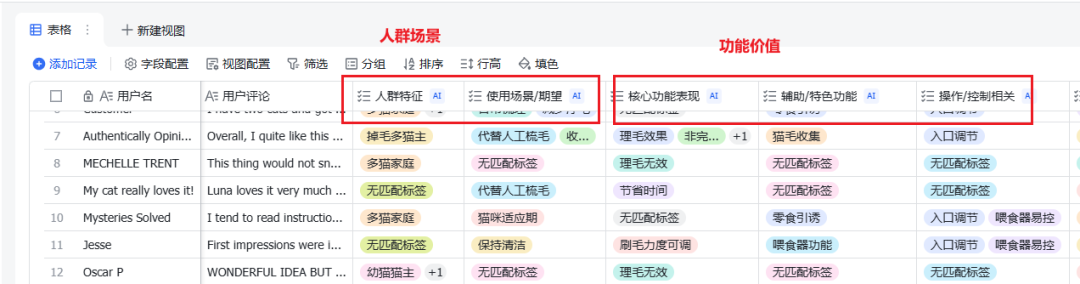

至此,我们最困难的打标签工作已经完成了。
虽然看起来很复杂,但实际上需要用到人脑的地方很少,都是交给AI去完成。工作量至少缩至30%数据分析
接下来攻克下一个难点——对标签进行
数据分析
开头说过了,直接把表格扔给AI去做数据分析,绝大部分情况下都是不靠谱的,数据都会有幻觉,也就是错的。
(虽然我不信邪,接连测试了Gemini 2.5 pro、Claude 3.7,最终得到的结果全是错的。所以你们不要再去试了)
现在的解决方案就是把表格扔给AI,让它学习表格结构后,生成Python代码,再去跑代码。不懂编程不要紧,基本上不怎么会报错,跟着执行就行了。
这里,我们可以用编程屠榜的gemini 2.5 pro 也可以用Claude 3.7,毕竟不是很复杂的代码需求。
提示词:
我在做用户购后评论洞察分析,现在已经完成了前两个阶段,得到了当前的表格,需要你帮我完成 `阶段三:数据分析与洞察提炼 (Data Analysis & Insight Extraction)`
具体的方法论如下(注意这个是通用方法论,是让你学习后再来分析我的表格的,而不是直接用里面的内容)
“`
把前面的方法论扔给AI学习
“`
只需完成 `阶段三:数据分析与洞察提炼 (Data Analysis & Insight Extraction)`即可其中人群/场景标签是:人群特征、使用场景/期望
功能价值是:核心功能表现、辅助特色功能、操作控制相关
保障价值是:产品质量耐用性、品牌服务支持、安全性可靠性
体验价值是:价格感知情感价值、感官体验、日常使用便携性、安装体验你的分析必须是基于对我的表格数据的统计
忽略「无匹配标签」
请给我做数据分析的python脚本完成定量数据分析的部分,注意,不需要做定性文字分析
不要生成图片,生成markdown形式的数据分析表格结果就行了
注意,这里的要点是最后的生成Markdown格式的结果,这个结果不是给我们自己看的,是方便给下一个AI来做分析。
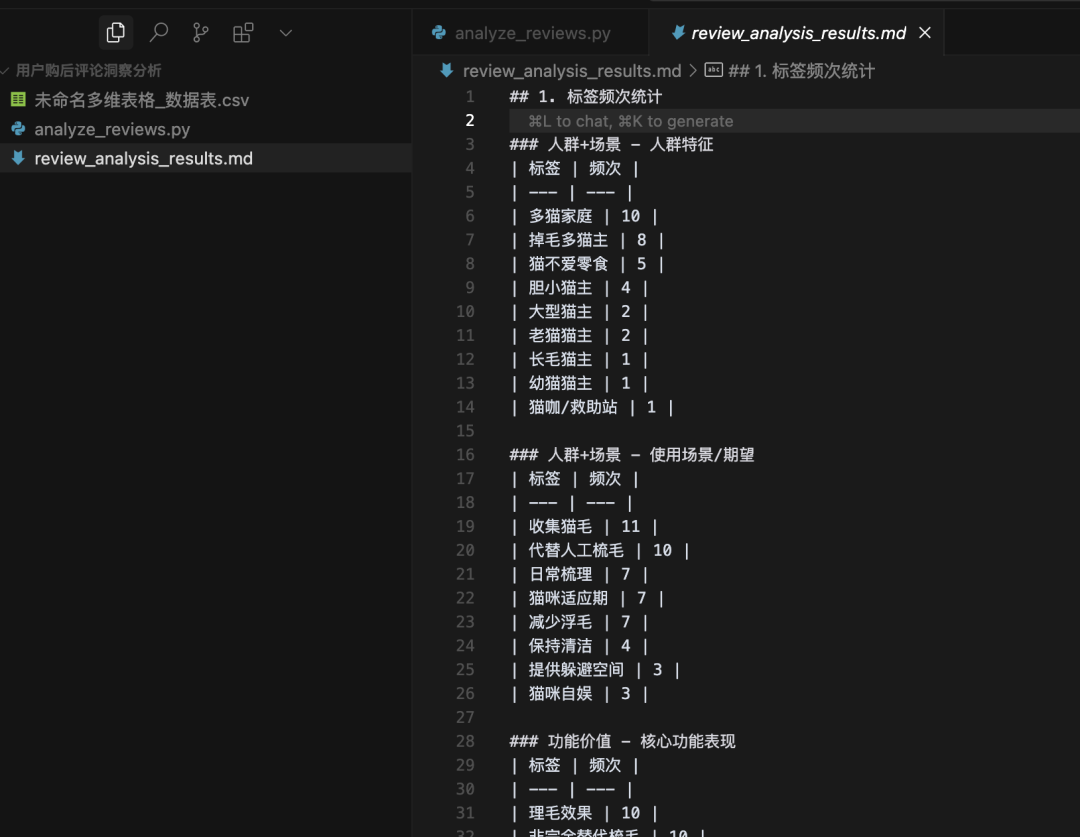
直接运行python脚本后,就会得到下图中的md文件,里面全是python做的各个维度标签的统计和多个维度标签交叉统计的数据结果。
换成Excel的话,也就是很多个sheet
这里可以简单自行做一下数据验证,我做过数据是正确的。
接着的事就简单了,直接把数据分析结果md文件扔给AI,记住是同一个对话框,因为前面AI已经学得了我们的分析框架,所以这里直接让它完成剩余步骤就好了。
这样我们就完成了数据分析的定性洞察。
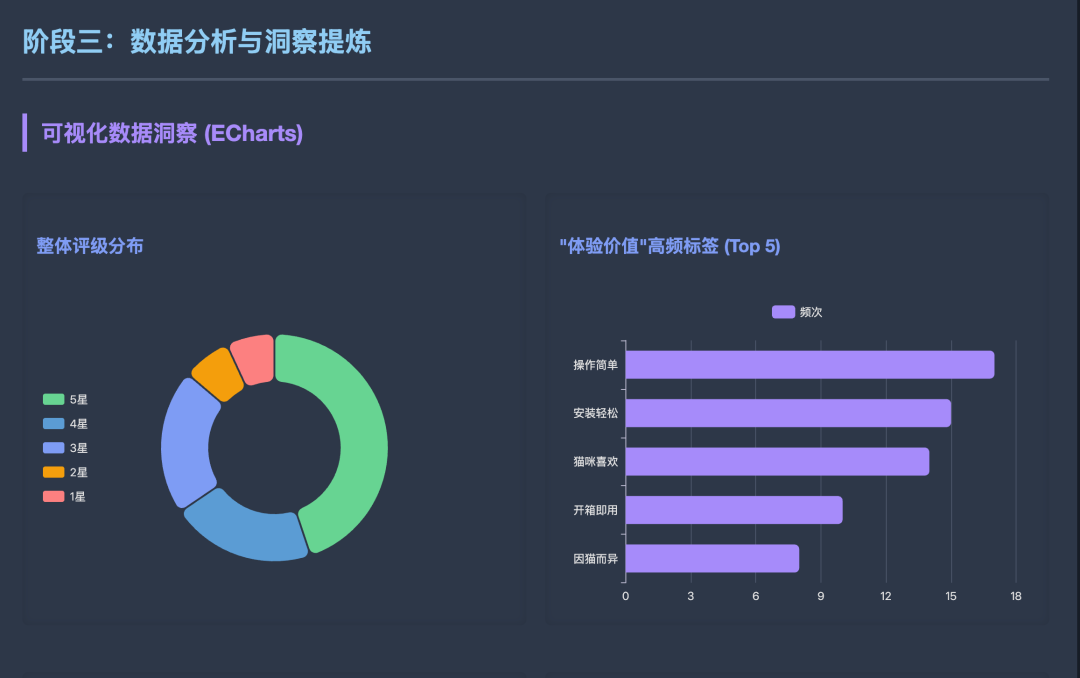
最后让AI做一个HTML分析报告,完结!
HTML的部分可以参考我之前这篇文章,得到一个动态的数据分析报告。

业务落地
饼干哥哥的风格从来不是讲虚的。这次分析案例之所以选择这个产品也是因为有朋友在做,跟她沟通后,也认可了此次分析报告结果,跟他们人工做的差不多,也能直接在营销策略上落地。对业务指导意义的话,反而是Step 5: 洞察提炼与解读会更有用一些。
当然,是否能在业务落地,还是要看不同公司的情况。
总结来说,需要遵循「以终为始」的逻辑:先从业务落地场景出发,倒推出分析框架和标签体系,再去做方案执行,就万无一失了。
作者【饼干哥哥】,微信公众号:【饼干哥哥AGI】