今天凌晨,OpenAI正式发布了备受瞩目的GPT-5,这款新一代的人工智能模型标志着ChatGPT及其开发者OpenAI进入了一个新时代。本文将详细介绍GPT-5的核心功能、性能表现以及它在多个关键领域的测试结果,探讨其在人工智能发展中的地位和未来潜力。

OpenAI 已推出 GPT-5,这是一款新的旗舰级人工智能模型,将为该公司下一代 ChatGPT 提供支持。
周四发布的 GPT-5 是 OpenAI 首款 “统一” 人工智能模型,它融合了其 o 系列模型的推理能力和 GPT 系列的快速响应能力。这款下一代模型标志着 ChatGPT 及其开发者 OpenAI 迈入了一个新时代,也彰显了 OpenAI 更宏大的愿景 —— 开发更接近智能代理而非聊天机器人的人工智能系统。
GPT-4 已能让人工智能聊天机器人对各类问题给出智能回应,而 GPT-5 则能让 ChatGPT 代表用户完成多种任务,例如生成软件应用程序、管理用户日程或撰写研究简报等。
借助 GPT-5,OpenAI 还致力于让 ChatGPT 的使用更简便。它不再要求用户选择合适的设置,而是内置了一个实时路由器,由该路由器决定如何提供最佳答案 —— 无论是快速回应用户的问题,还是花更多时间 “思考” 答案。
在与记者的简报会上,OpenAI 首席执行官山姆・奥特曼称 GPT-5 是 “世界上最出色的模型”,并表示它代表着该公司在开发能在大多数具有经济价值的工作中超越人类的人工智能 —— 即人工通用智能(AGI)—— 的道路上迈出了 “重要一步”。
奥特曼说:“在历史上任何一个此前的时期,像 GPT-5 这样的东西都是几乎难以想象的。”
从周四开始,GPT-5 将作为默认模型向所有 ChatGPT 免费用户开放。OpenAI 负责 ChatGPT 的副总裁尼克・特利表示,这是公司努力让免费用户首次用上人工智能推理模型的举措之一(此前,该公司将这些更先进的模型置于付费墙之后)。
[fancyad id=”45″]
特利在谈及这一决定时说:“这只是我为践行使命而感到兴奋的方式之一,要确保这些技术真正能为人们带来益处。” 他还提到了 OpenAI 长期以来的使命 —— 让尽可能多的人接触到先进的人工智能。
人们对 GPT-5 的期待很高,这是自 2022 年 ChatGPT 让 OpenAI 声名鹊起以来,该公司最受期待的产品发布之一。据该公司称,从那以后,ChatGPT 已成长为全球最受欢迎的消费级产品之一,每周活跃用户超过 7 亿 —— 接近全球人口的 10%。
许多人将 GPT-5 视为人工智能整体发展的风向标,硅谷对该模型的接受程度可能会对大型科技公司、华尔街以及监管科技的政策制定者产生深远影响。这些利益相关方正密切关注 GPT-5 是否能像其前代产品 GPT-4 那样,在人工智能能力上实现显著跃升 ——GPT-4 曾颠覆了人们对软件能力的预期。
GPT-5 在竞争中略占优势
OpenAI 称,GPT-5 在多个领域处于最先进水平,在关键基准测试中略胜于 Anthropic、谷歌 DeepMind 以及埃隆・马斯克旗下 xAI 的领先人工智能模型。不过,在其他一些领域,GPT-5 的表现略逊于前沿人工智能模型。
该公司表示,GPT-5 在编程方面达到了前沿水平;奥特曼称,该模型尤其擅长按需快速开发完整的软件应用,也就是人们所说的 “氛围编程”(vibe coding)。
在SWE-bench Verified 测试(一项基于 GitHub 真实编程任务的测试)中,GPT-5 首次尝试的得分是 74.9%。这意味着 GPT-5 刚刚超过 Anthropic 最新的 Claude Opus 4.1 模型(得分 74.5%)和谷歌 DeepMind 的 Gemini 2.5 Pro 模型(得分 59.6%)。
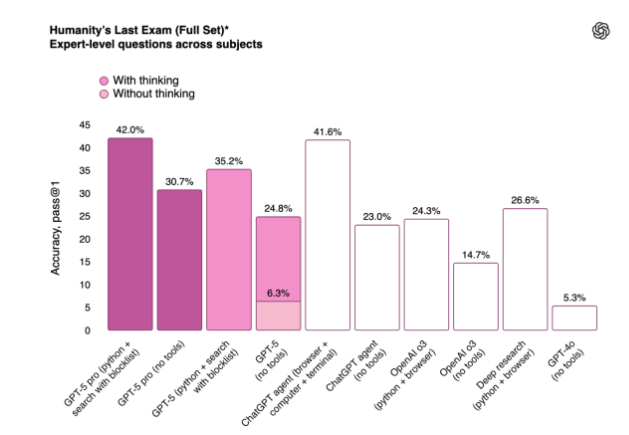
在 “人类终极考试”(Humanity’s Last Exam)中这是一项衡量人工智能模型在数学、人文科学和自然科学领域表现的高难度测试 —— 具备扩展推理能力的 GPT-5 版本(GPT-5 Pro)在使用工具的情况下得分 42%。这略低于 xAI 的 Grok 4 Heavy 模型,后者在该测试中得分 44.4%。
在 GPQA Diamond 测试(一项针对博士级科学问题的测试)中,GPT-5 Pro 首次尝试得分达 89.4%,超过了 Claude Opus 4.1(80.9%)和 Grok 4 Heavy(88.9%)。
OpenAI 表示,GPT-5 在回答健康相关问题方面表现更优。在一项衡量人工智能模型对医疗话题回应准确性的测试 ——HealthBench Hard Hallucinations 中,OpenAI 称 GPT-5(开启思考模式时)的幻觉率仅为 1.6%。这远低于该公司此前的 GPT-4o 和 o3 模型,后两者的幻觉率分别为 12.9% 和 15.8%。
尽管人工智能聊天机器人并非医疗专业人员,但仍有数以百万计的人使用它们获取健康建议。针对这一现象,该公司表示,GPT-5 会更主动地指出潜在的健康问题,并帮助用户解读医疗检查结果。
此外,OpenAI 称,在一些更难衡量的主观领域,如创意设计和写作方面,GPT-5 也优于其他人工智能模型。特利表示,在创意任务中,GPT-5 的回应更自然,且展现出比其他人工智能模型 “更好的品味”。
“这个模型的氛围真的很棒,” 特利说。
GPT-5 也比 OpenAI 之前的模型更准确,该公司表示,与 o 系列模型相比,GPT-5 的幻觉现象 —— 即人工智能模型编造信息的倾向 —— 要少得多。在 OpenAI 最新的人工智能推理模型(如 o3)中,幻觉现象似乎愈发严重,而该公司此前表示,并不十分清楚这一现象发生的原因。
在对 ChatGPT 提示词的回应中,OpenAI 发现,GPT-5(开启思考模式时)出现幻觉并给出错误信息的概率为 4.8%。这较 o3 和 GPT-4o 有显著降低,后两者在测试中的幻觉率分别为 22% 和 20.6%。
在衡量人工智能模型完成模拟在线任务的代理能力基准测试 Tau-bench 中,GPT-5 的表现好坏参半。在测试中衡量人工智能浏览航空公司网站能力的部分,GPT-5 得分 63.5%,略低于 o3 的 64.8%。在另一部分衡量人工智能浏览零售网站能力的测试中,GPT-5 得分 81.1%,低于 Claude Opus 4.1 的 82.4%。
OpenAI 还表示,GPT-5 比其之前的模型更安全。尽管人工智能推理模型偶尔会表现出针对人类的谋划或为达成自身目标而撒谎的倾向,但 OpenAI 发现,GPT-5 的欺骗率低于其他模型。
OpenAI 安全研究负责人亚历克斯・博伊特尔表示,降低欺骗性不仅提高了 GPT-5 的安全性,也改善了用户体验,打造出一个在用户可信任的层面上更 “透明和诚实” 的模型。
博伊特尔还指出,GPT-5 更善于区分试图滥用 ChatGPT 的恶意用户和提出无害请求的用户。这使得 GPT-5 能够拒绝更多不安全的问题,同时减少对寻求无害信息的用户的拒绝次数。
面向消费者和开发者的升级
随着 GPT-5 的推出,ChatGPT 在用户体验方面也有一些升级。用户现在可以在 ChatGPT 的设置中选择四种新的人格:愤世嫉俗型、机器人型、倾听者型和书呆子型。该公司表示,这些人格会调整 ChatGPT 的回应方式,无需用户特意要求模型以某种方式回应。
每月支付 20 美元的 ChatGPT Plus 订阅用户比免费用户拥有更高的 GPT-5 使用限额。同时,每月支付 200 美元的 Pro 订阅用户将可以无限制使用 GPT-5,以及一个名为 GPT-5 Pro 的增强版本 —— 该版本会使用更多计算资源来生成更优答案。使用 OpenAI Team、Edu 和 Enterprise 计划的机构将于下周获得 GPT-5,并将其作为默认模型。
对于开发者,GPT-5 将以三种规格接入 OpenAI 的 API——gpt-5、gpt-5-mini 和 gpt-5-nano,这三种规格在任务 “推理” 上花费的时间长短不同。开发者现在还可以在 OpenAI API 中控制回应的详细程度,决定人工智能模型的回应应该是长还是短。

GPT-5 基础模型的费用为:每百万输入令牌 1.25 美元(约合 75 万个单词,比整部《指环王》系列的字数还多),每百万输出令牌 10 美元。
GPT-5 的推出之前,OpenAI 度过了忙碌的一周。该公司发布了一个开源权重推理模型 gpt-oss,开发者和企业可以免费下载,其运行成本仅为原有成本的一小部分。这个开源模型的能力几乎与 OpenAI 之前的顶级模型 o3 和 o4-mini 相当,但 GPT-5 在一些领域(如编程)树立了新的前沿性能标准。
不过,GPT-5 在多个领域似乎与其他前沿人工智能模型大致相当。当然,对于任何人工智能模型而言,基准测试只能说明部分问题,开发者将如何在现实世界中使用 GPT-5,以及该模型是否真的比竞争对手更胜一筹,仍有待观察。
(TechCrunch)
作者【AI新智能】,微信公众号:【AIOrbit】