AI Agent的热度持续升温,但真正的成功并不在于“看得见”的功能,而是藏在底层的系统设计与业务理解中。本文从“冰山模型”出发,拆解AI Agent落地的关键要素,揭示那些被忽视却决定成败的90%隐性工程。

在聊 Agent 之前,我想先带大家看看一位“圈内大佬”的看法。
他就是 OpenAI 的 CEO,山姆·奥特曼(Sam Altman)。奥特曼曾分享过他对通用人工智能(AGI)进化路径的洞察,将AI的发展分成了五个阶段。
如果把通往 AGI 的道路比作一场升级打怪,目前我们发展到哪个阶段了呢?
- L1阶段,Chatbot像ChatGPT3.5这样的“聊天机器人”。它能理解和生成文本,像一个聪明但缺乏行动力的大脑。
- L2阶段,Reasoner像DeepSeek、OpenAI-O1一样具备“推理能力”(Reasoner)的模型。它们能进行复杂的多步思考,也就是我们常说的“思维链”(ChainofThought),让AI学会了“如何思考”。
- L3阶段,Agent便是我们今天的主角——“智能体”(Agent)。在这个阶段,AI不仅能思考,还被赋予了“手和脚”,可以自主地与外部世界交互并完成任务。
- L4阶段,Innovator是“创新者”。AI能自主进行科学研究和产品创新,生成全新的知识。
- L5阶段,Organizations是“组织”。AI能够像一个公司一样,处理所有任务,一个AI就能完成整个公司的工作。
山姆·奥特曼在早期的访谈中,就曾分享过他对AGI进化路径的洞察。当时这些展望还停留在理论,而如今,他的预言正在一步步变为现实。
没错,我们当前就处在L3,Agent阶段。
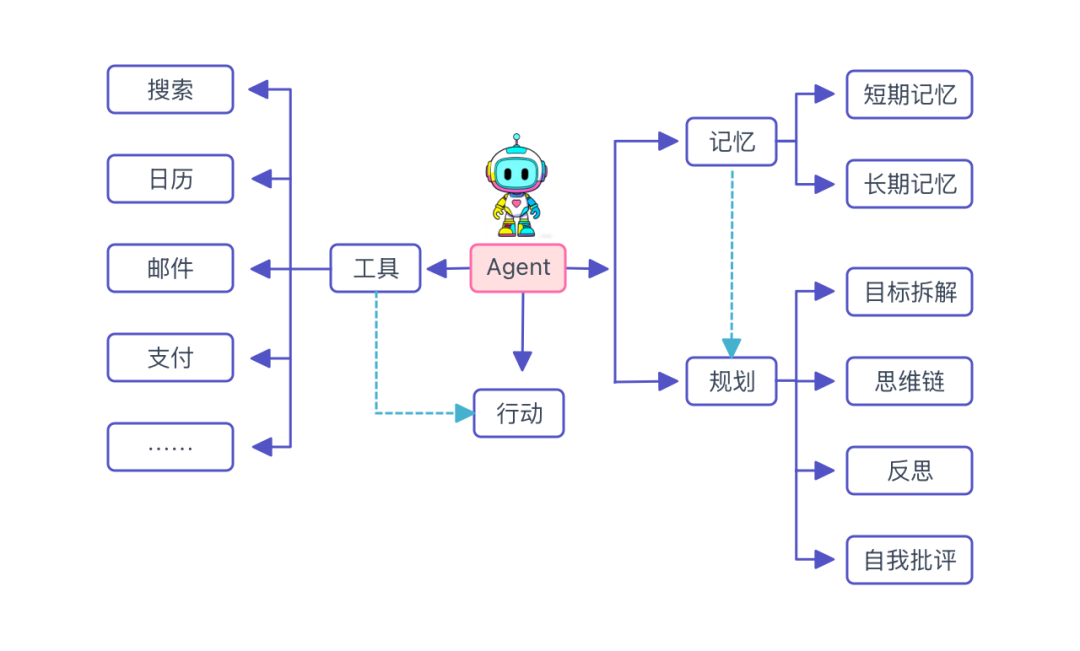
Agent是什么?
Agent 是一种能够观察世界、调用工具并采取行动以实现特定目标的大模型应用;它不仅具备自主性,还能主动推理下一步策略。
网上有各种定义,我认为解释得最好的是Anthropic: Agent是让模型基于环境反馈去使用工具的一个程序。
说得更通俗易懂一些:像人一样执行任务。
像人一样执行任务,人类和AI的行为模式到底有哪些区别呢?
人类和AI的行为模式区别
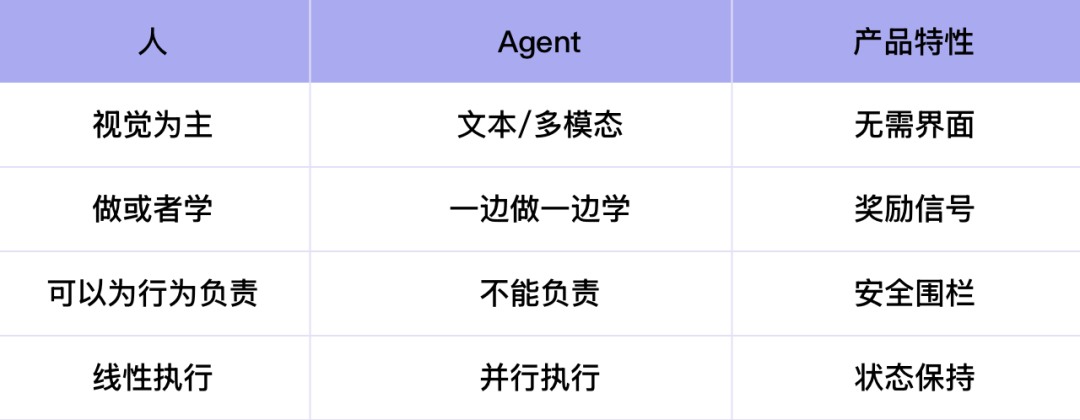
第一个区别:交互方式
我们人类是“视觉动物”,人类的交互主要依赖视觉,因此为人类设计的产品需要一个前端界面,而 Agent 则可以通过文本和多模态在后端实现交互。
第二,人需要“专注”,AI能“一心多用”
人类无法同时「做事情」和「学东西」,因为这两者涉及到大脑的不同区域。但 Agent 却可以通过强化学习,在执行任务的同时进行学习。因此,为 Agent 设计产品时,至关重要的是设计一套奖励机制。
举个例子,当你使用浏览器时,系统不会频繁弹出窗口来评价你的操作是否正确。但如果是为 Agent 设计的浏览器,就需要时时提供 +1分,以便它在下次执行任务时表现得更好。
第三个区别是单线程 VS 多线程
有一个经典的对比:人的工作模式很像“贪婪算法”,总是关注眼前最有利的局部最优解,一步步完成任务。上一个任务的结束,就是下一个任务的开始,是一种单线程的逐一完成模式。
而 AI 的模式则很像「动态规划」,它能同时在多个节点上并行处理很多任务,始终追求全局最优解。
不过这也引发了一个问题:当 Agent 并发执行任务时,该怎么保持不同任务的状态?
对于人类来说,上一个任务的结束就是下一个任务的开始,因此天然不需要去保持状态。
然而,Agent 在一个节点上可能同时执行 100 个任务,这些任务的执行速度各异,有些快,有些慢,甚至有些可能需要人工干预,所以需要设计一种新的机制保证 Agent 能高效稳定地在不同任务间切换和协调。
第四个区别:人的边界,AI的“安全围栏”
人可以为自己的行为负责,但如果一个AI Agent出了问题,谁来承担责任?
比如你手里有一段代码,如果这段代码是你自己写的,你当然可以接受这段代码直接在你的电脑上运行,因为出了问题你可以负责。
但如果这段代码是 AI 生成的呢?如果运行之后,你的文件全丢了,谁来负责?
为了解决这个难题,AI Agent执行任务时最基本的要求,就是要有一个“安全围栏”(Sandbox,沙盒)。这个围栏就像一个虚拟的保护罩,将AI产生的影响控制在一个安全的范围内。
这个安全围栏并不是要一刀切地限制住 Agent 的能力,而是要动态判断哪些任务和信息可以交由 Agent 处理,而哪些不能。
AI Agent 技术栈全景
虽然我们看到的大部分“智能”表现来自顶层的 AI 模型,但真正支撑 Agent 运作、使其可靠和强大的,是水面下的庞大工程体系。
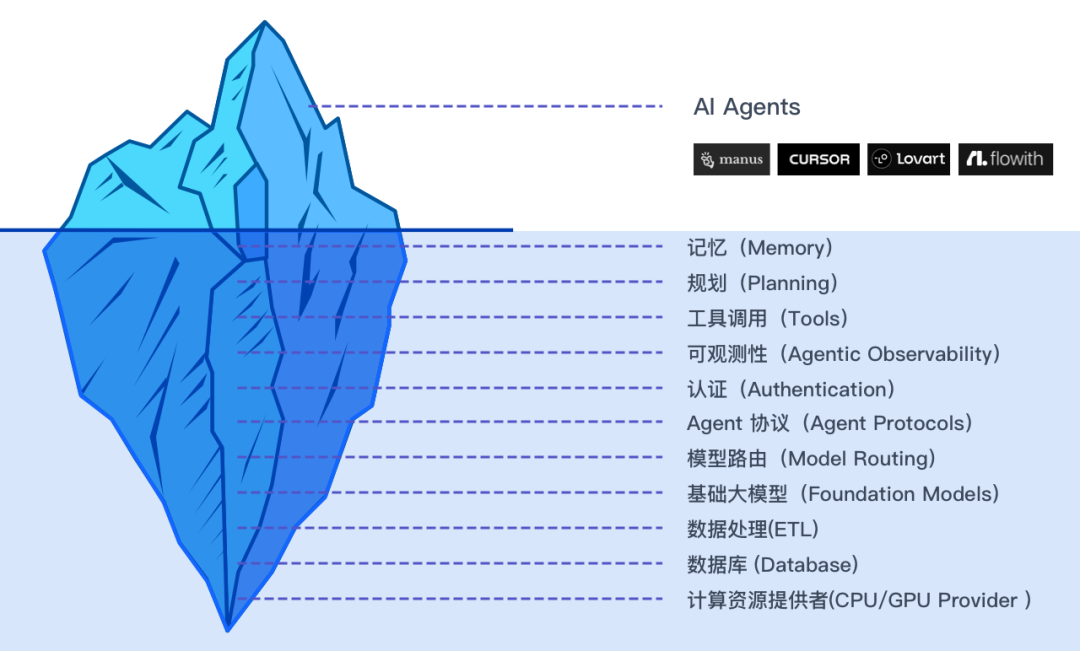
给大家举个通俗易懂的例子:将AI Agent比作一辆车,大模型就是发动机,但是还需要方向盘,车轮子、油路、电控系统等。
从水面上的应用层到水面下的技术基座,我将逐一给大家讲个明白~
水平面顶层–AI Agents 应用层
这是冰山顶端,也是咱们用户直接接触到的产品。
市场上比较火的Agent产品有:Manus、Flowith、Lovart、Cursor、Harvey等

现在,让我们一起“潜入”水下,看看一个AIAgent到底是如何工作的。看看 AI Agent为了能真正地给人类干活,到底付出了多少的努力。
中层:AI Agent 核心能力与工程支撑
1. 规划——Agent的“大脑管家”
没有规划的 AI,就像一个没做复习提纲的学生,回答问题可能思维跳来跳去、不够全面。 有了规划的 AI,才会更像一个靠谱的助手:懂目标、会拆解、能反思,还能自己改进。
规划的四大能力
1)目标拆解(Subgoal Decomposition)
把一个大任务拆解成可执行的小任务,类似于to do list。
把“策划发布会”分解成“找场地”、“做PPT”、“写宣传文案”等小任务。这个环节才是Agent真正强大的地方,也是它能处理复杂问题的关键。
2)思维链(Chain of Thoughts)
一个聪明的项目经理,在分配任务之前,会先在脑子里把整个流程“想”一遍。AI Agent也一样,它会先在“大脑”里跑一遍自己的思维链,这就是Chain of Thought(简称COT)
再给大家举个例子方便理解:比如,我让Agent写一篇关于AI Agent的文章时,它不会立刻动笔。它会先在内部进行一个“头脑风暴”:
第一步:需要上网搜集关于Agent的最新论文;
第二步:分析这些论文,找出核心观点;
第三步:根据这些观点,生成文章大纲;
第四步:根据大纲填充内容……
这个一步步‘想’的过程,就是AI领域的“思维链”(Chain of Thought)。”
正是因为有了这个“思维链”,Agent才能将一个复杂、模糊的任务,变成一个清晰、可执行的计划。它不仅能帮助Agent完成任务,还能在任务失败时,让Agent知道问题出在哪里,从而进行自我修正。
所以说,“思维链”是Agent拥有强大“任务管理”和“自我纠错’能力的关键。它就像是Agent的“内在独白”,让它从一个简单的执行者,进化成一个真正会思考的智能体。”
3)反思(Reflection)
让 Agent 在完成任务后,回顾自己做得到底对不对。
写完一段代码后,Agent 会检查:
- 有没有语法错误?
- 输入输出逻辑是否合理?
就像人写完文章后会“回头读一遍”一样,检查有没有逻辑错误,有没有错别字,标点符号是否正确等。
4)自我批评(Self-Critics)
让 Agent给自己挑毛病,然后改进。
AI 写了一篇文案,自己会问:
- 有没有错别字?
- 有没有逻辑重复?
- 有没有更吸引人的说法?
然后再从表达上润色一遍。
自我批评,让 AI 从“只会输出”进化到“会自我迭代”。
这也是我为什么说规划是Agent的“大脑管家”,因为它不仅帮你执行,还会提前计划、过程监督、事后复盘。
2. 记忆(Memory)
记忆(Memory)是什么?
在大模型里,记忆(Memory)就像人的大脑记忆:它帮助模型不仅能“即时对话”,还可以“有前后文”、“能记住事情”。
如果没有记忆,模型每次回答问题都像失忆了一样:用户一旦关掉对话窗口,它就不记得之前发生的事。
有了记忆之后,AI 才能变得更像“一个真正的助手”——懂你、记得你、会总结你的习惯。
1)短期记忆(Short-term memory)
对应上下文窗口(Context Windows)。
就像人的“工作记忆”,只能记住你最近聊过的内容。
举例:
你说:“我叫小宋。”
接着问:“我刚刚说我叫什么?”
AI 能回答“小宋”。

但是上下文窗口他是有大小的。比如:
- GPT-2的最大上下文窗口是2048tokens,大概是2K个Token,相当于1~1.5页A4正常排版的文字内容;
- GPT-3:上下文窗口为4096tokens,大概是4K个Token,相当于可以容纳一整篇新闻特写/报告文章;
- GPT-4:上下文128,000tokens,大概是128K个Token,可以容纳一部中长篇小说的全部内容。例如,J.K.罗琳的《哈利·波特与魔法石》英文版约77K单词,完全能放入上下文中。
但是如果你聊太久,超过了它的“记忆上限”,旧的内容就会被遗忘(像人聊天聊久了忘了开头说了什么)。
2)长期记忆(Long-term memory)
对应RAG(检索增强生成)+ 知识库。这里就不展开讲了,对 RAG 感兴趣的同学请看我上一篇哟~
就像人的“长期记忆”,能保存很久,不会轻易忘掉。
举个例子:
你上传一份金融公司的产品手册,让 AI 记住。
下周再来问:“我们的产品支持哪些功能?”
它可以从知识库里检索出来再回答你。
这就是通过知识库 + 向量数据库 + RAG 技术实现的。
像人企业私有知识库问答、AI 助手可以记住你的长期偏好(比如你喜欢的写作风格)等,这就是长期记忆。
那咱们来总结一下:
- 短期记忆=临时记忆,靠上下文窗口,容量有限,容易遗忘。
- 长期记忆=持久记忆,靠知识库(RAG)保存,随时可检索。
两者结合,就让 AI 更像一个“会思考、能记忆的人”。
3. 工具调用(Tools)——AI的“手和脚”
如果把记忆(Memory)看作大脑的“记忆能力”,规划(Planning)看作大脑的“思维能力”, 那么工具调用(Tools)就是给 AI 装上的“外挂超能力”。
没有工具调用的 AI,就像一个只会在脑子里想的学生;
有了工具调用的 AI,就像一个带着计算器、搜索引擎、Excel、画图软件的学霸,能动手解决更复杂的问题。
举个例子,你让一个设计员工去完成一个复杂的任务。他不仅要有一个聪明的大脑,去迸发灵感。还需要各种工具,比如说:Photoshop、Figma、Sketch等设计工具。
AI Agent也是一样,它的“手和脚”就是各种工具(Tools)。
常见的工具包括:
- 搜索引擎:Google、必应、百度(补充最新信息)负责上网查资料;
- 数据分析工具:Pandas、ExcelAPI(做计算、画图表)
- 知识库:企业内部文档、向量数据库(找资料更精准)
- 第三方应用:调用日历、邮箱、翻译API、支付系统等
有了这些工具,AI 不再只是“说一说”,而是真能“动手去做”。没有这些工具,再聪明的AI也只能“纸上谈兵”。
4. 可观测性(Agentic Observability)
可观测性就是让 AI Agent 变得透明可控: Agent不再是“黑箱”,而是一个可以随时体检、随时定位问题的系统。
1)为什么 AI Agent 特别需要可观测性?
和普通软件不同,AI Agent 的运行过程有很多“不可预测”的地方:
- 模型回答可能偏题
- 工具调用顺序不对
- 多个Agent协作时,可能出现“踢皮球”的情况
- 成本(Token/API调用)一下子飙升
如果没有可观测性,你根本不知道Agent 为什么出错、哪里耗时、钱花在哪了,就很难定位问题。2)可观测性包含哪些维度?
日志(Logs)
- 记录每一步操作,比如调用了哪个模型、传入了什么参数。
- 就像写日记,方便追溯问题。
指标(Metrics)
- 统计运行情况,比如响应时间、成功率、Token消耗。
- 就像体检时候的血压、心率,让你知道系统是不是健康。
追踪(Tracing)
- 就像快递的物流跟踪,让你清楚看到包裹的每一站。
- 记录一次完整请求的“旅程”。
比如:用户提问 → 路由到 GPT-4 → 调用 Google Search → 整合答案。
3. 常见工具和框架
在 AI 领域,常见的可观测性平台有:
国外:
- Arize:专注模型监控,发现AI回答是否有偏差。
- LangSmith(LangChain团队出品):跟踪Agent的调用链路,方便调试。
- LangFuse:开源方案,能监控LLM调用和指标。
- Helicone/Opik:帮助开发者记录和分析API调用,追踪成本与效果。
国内:
- 阿里云+中国信通院定义了LLM应用在训练、推理等环节中,要哪些可观测性能力(比如日志、追踪、异常检测、性能监控、安全监控等)。帮助企业知道“应该做哪些监控”,构建可观测性体系。
- OpenLLMetry——开源的LLM可观测性方案,为LLM应用提供可观测性工具。可能包括采集指标、显示仪表板、告警等。
- 华为云ModelArts支持模型的在线服务监控、负载监控、性能指标、资源占用、告警等。
5. 认证(Authentication)
在 AI Agent 的技术栈里,认证是非常基础但关键的一层。 很多同学可能会有疑惑:Agent 不就是回答问题嘛,为什么还要认证?
没有认证的 AI Agent,就像一个办公楼没有门禁卡 — 谁都能进来,既不安全,也不可控。
1)为什么需要认证?保护用户身份
比如一个企业内部 Agent,只有员工能用,外人不能随便调用。
保护数据安全
AI Agent 往往要接触隐私数据(聊天记录、公司资料、数据库)。
没有认证,就可能被恶意调用,造成数据泄漏。
控制权限和范围
不同的人可以配置不同的功能权限。
比如:员工可以查考勤,管理员才能批量导出报表等
审计与追踪
谁访问了 Agent、做了哪些操作,都能记录下来。
方便日后追溯问题。
2)常见的认证方式
在 AI Agent 系统中,常见的认证方式有以下几种:
账号 + 密码
最传统的方式,适合个人小工具,但安全性一般。
OAuth 2.0 /OpenID Connect
比如用微信 / 钉钉 / GitHub / Google 登录第三方网站。
常见于企业级 Agent 系统。
APIKey(密钥)
调用 Agent 接口时,必须带上一个“钥匙”。
就像去酒店开门,要插房卡。
多因素认证(MFA)
除了密码,还要短信验证码 / 邮件验证 / 动态口令。
常见于对安全要求极高的 Agent 应用。
基于角色的访问控制(RBAC)
比如后台交易系统中,我们会设置“普通用户”“管理员”“超级管理员”。
不同角色分配不同权限。
在AIAgent 的技术栈里,认证保证了谁能用、能用到什么程度、做了什么操作变得可控了起来。
6. Agent 协议(Agent Protocols)
定义了 Agent 之间如何通信和协作的标准。解决不同 Agent、不同模型之间的沟通问题,相当于“翻译官 + 调度员”。比如Google提出的A2A(Agent2Agent开放协议)、Tidal、SLIM、IBMACP等都是正在发展的相关协议。
7. 模型路由(Model Routing)
Model Routing (模型路由):决定在特定任务下,应该使用哪个底层大模型。
很多小白第一次听到Model Routing(模型路由),都会一脸懵: 听起来像是“模型走高速公路”吗? 其实并不复杂,它就是在多个大模型之间,智能地帮你选最合适的那个。
比如,一个 Agent 可以根据任务类型,自动选择调用Deepseek、Kimi、Claude、Gemini或OpenAI等不同模型。
再举个通俗易懂的例子:
在你的公司里,有好几个员工,他们有不同的擅长点:
- 小张:逻辑清晰,擅长写代码。
- 小李:文笔很好,适合写文案。
- 小王:知识面广,擅长搜索和总结。
现在你接到一个任务:
- 如果是写文案→应该派给谁?派给小李
- 如果是写SQL→应该派给小张
- 如果是查资料→应该派给小王
这背后“派单”的人,就是 ModelRouter(模型路由器)。
通过我的例子,相信大家可以大致猜出模型路由的优势了。
优势 1:降低成本
简单问题(比如算个加减法),用便宜的小模型就够了。
复杂任务(比如写一篇长文),再调用 GPT-4、Kimi、 Gemini 这种大模型。
优势 2:提升效果不同模型有擅长的领域。比如 Claude 擅长总结长文,GPT-4 擅长推理、Gemini擅长多模态和全球生态整合等,路由器会“对症下药”。优势 3:智能分流
同时接入多个模型供应商(OpenAI、Anthropic、Gemini、deepseek、kimi等),系统会根据任务类型自动分配,避免“只用一个模型”。
底层:硬件与基座——AIAgent的“地基”
在最底层,是支撑一切运作的硬件(CPU/GPU)和基础设施(Infra)。这就像一个公司的办公室和水电网。没有这些,再好的项目经理和工具也无法运作。
我们平时说的ChatGPT、Claude、Deepseek这些大模型,其实只是这个地基上的一颗强大芯片,它提供“思考”的能力,但不是全部。
1. 基础大模型(Foundation Models)
在Agent这座“超级智能城市”中,我们已经聊了它的“手脚”(工具)、“记忆”(数据库)和“交通网络”(基础设施)。现在,终于要讲到这座城市最核心、最神秘的部分——基础大模型(Foundation Models),它就是Agent的“中央大脑”。
为什么说它只占10%?
尽管大模型是Agent的“大脑”,但为什么说它只占整个Agent成功的10%?
- 没有“手脚”的大脑是无用的。一个再聪明的人,如果不能使用工具、不能与外界交互,也无法解决实际问题。Agent的大模型虽然能生成优秀的“思维链”,但没有“工具”层去执行,它就无法真正改变世界。
- 没有“记忆”的大脑是健忘的。大模型虽然强大,但它无法记住你和它的所有历史对话。Agent之所以能保持长期连贯性,靠的是外部的“记忆”系统,而不是大模型本身。
- 基础大模型是Agent的核心引擎,提供了最基础也最强大的“智能”。但它不是Agent的全部。
一个优秀的 Agent,就像一个优秀的团队:它需要一个聪明的“大脑”(基础大模型)来做决策,也需要有力的“手脚”(工具)来执行,更需要可靠的“记忆”(数据库)来提供支持,还需要强大的“基础设施”(硬件与基座)来保障稳定。
2. 数据处理(ETL)
ETL 是Extract(提取)、Transform(转换)、Load(加载)三个英文单词的首字母缩写,它就像一个“原料工厂”,确保送到Agent面前的都是高质量、可直接使用的信息。
数据处理是一个不起眼但至关重要的环节。它决定了Agent所能获取的知识的质量和广度。
一个强大的Agent,背后一定有一个高效的ETL系统,能源源不断地为它输送高质量、结构化的“数字养料”。这正是软件工程在Agent领域发挥巨大作用的又一个体现。
3. 数据库 (Database)
Agent 的“长期记忆”需要一个地方存储。向量数据库,如Chroma和Pinecone,就是专门为它建造的“图书馆”,能快速存取和检索海量的知识和信息,确保 Agent 在需要时能迅速调取相关记忆。存储 Agent 的长期记忆和相关数据。
4. 计算资源提供者(CPU/GPUProvider )
Agent 的所有智能活动,从思考、规划、调用工具,到最终生成结果,都需要庞大的计算力。而这些计算力主要由GPU(图形处理器)和CPU(中央处理器)提供。
计算资源提供者是 Agent 存在的物质基础。它们提供的强大算力,就像是为 Agent 注入了生命力。没有它们,Agent 的所有设想都只是空谈。
结尾:AI Agent的终极意义
所以说,一个成功的AI Agent,不只是一个聪明的大模型,而是一个由前端、记忆、工具、任务编排等一系列复杂系统共同组成的“超级工程”。
这也解释了为什么许多科技巨头都在抢占 AI Agent 的赛道。因为这不再是简单的模型之战,而是系统集成、工程化能力和行业理解的综合较量。
未来
未来, 我认为一定是多智能体的形式( Multi-Agents)。为什么这么说呢?无论是Google提出的A2A(Agent2Agent开放协议,还是红杉提出的 Agent swarms (智能体集群)都在表达Agent与Agent之间的沟通是未来必然会发生的事情。
AI Agent的未来在于垂直化和工程化,通过多Agent的共同协作,它将渗透到我们工作和生活的方方面面。
AI Agent将像水电煤一样,成为我们工作和生活的基础设施。而那些能把“冰山”水下部分做得又深又稳的公司,才是真正的赢家。
你觉得,未来哪一个领域的AI Agent会率先改变我们的生活?在评论区聊聊你的看法吧!
以上,既然看到这里,如果觉得不错,随手点个赞、收藏吧。如果想第一时间收到推送,也可以给我个星标哟🌟~谢谢你的喜欢,我们,下次再见吧~
作者:March