OCR技术的演进,正在从“识别能力”走向“压缩效率”。本文深度解析DeepSeek-OCR如何通过上下文光学压缩实现SOTA级性能,以更少的视觉Token完成更精准的识别任务,重塑AI文档解析的工程范式,为产品人和技术团队提供一套可部署、可扩展的智能入口。

之前和 OpenAI 的做交流,突然提了一个问题文字,是信息压缩的最好方式吗?
当时没想太多,直到今天DeepSeek 开源了 DeepSeek-OCR用 10 个视觉 token,表达 100 个文本 token
github.com/deepseek-ai/DeepSeek-OCR
我突然意识到:这个问题可能有答案了具体对比:
- DeepSeek-OCR用100个token,超过了GOT-OCR2.0的256个token
- DeepSeek-OCR用800个token,超过了MinerU2.0的6000+token
- 即使压缩到20倍,准确率还有60%
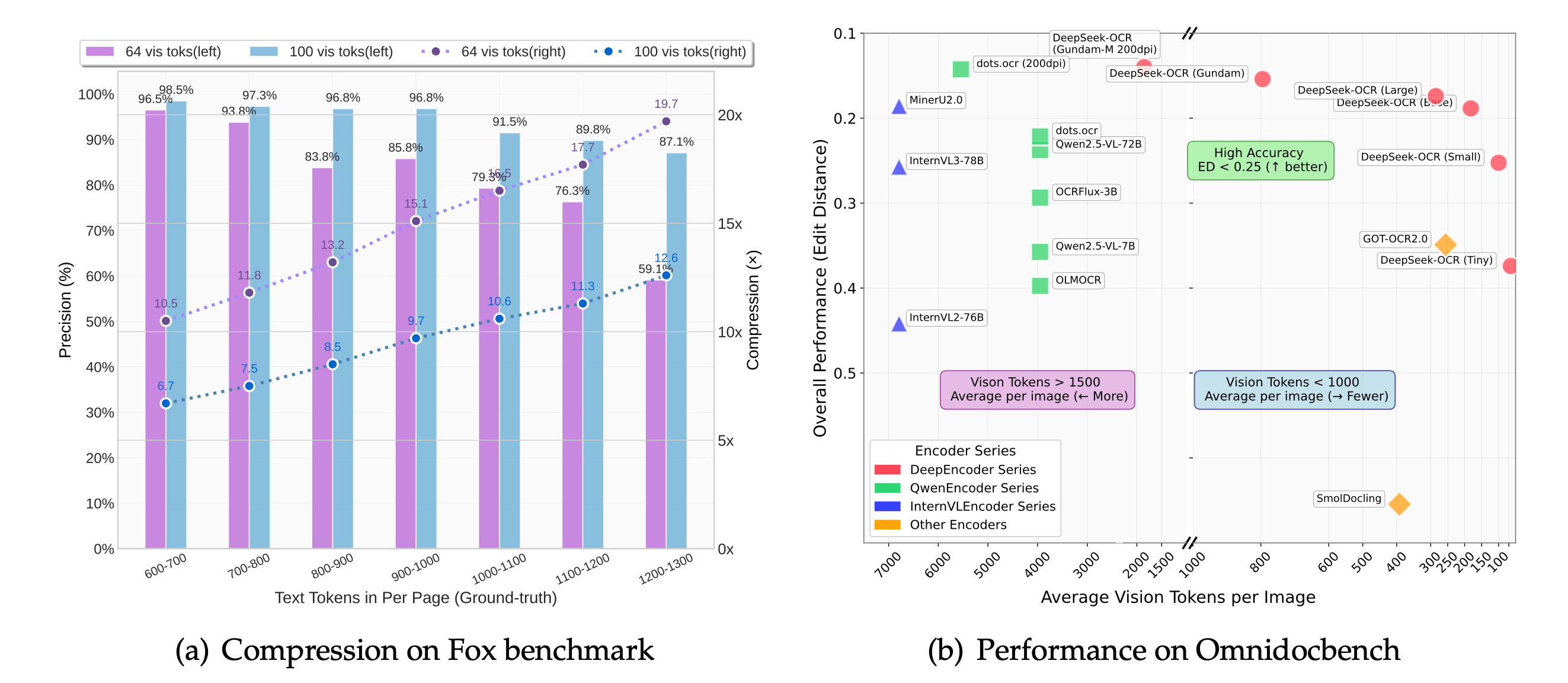
DeepSeek-OCR在不同压缩比下的准确率
为什么重要
现在所有的多模态大模型都面临一个瓶颈:token 消耗太多了
处理一页 PDF 就要消耗几千个 token如果你想处理一本书、一份研究报告、一堆财务文档context window 立刻就爆了每个 token 都要算钱、消耗显存、拖慢推理速度
DeepSeek-OCR 用数据告诉你10 倍压缩,几乎无损
信息论视角
对于这个问题Hacker News 上展开了很大的讨论
是当前 Hacker News 上的最火话题
“为什么这种方法有效?”
“是不是文本 token 太粒状了,没接近理想的熵编码?”
“切换到视觉 token 是不是逃脱了’一次一个词’的限制?”

Hacker News 评论第一条
有个回答说的很有意思文本 token 本质上是离散的查找表你有个小整数(token ID)然后查表得到一个向量
但视觉 token 是连续值向量没有查找表直接从图像编码成向量
这意味着什么?文本 token 的「token 空间」是有限的通常就 10 万个可能的 token每个 token 对应一小段 UTF-8 字节而且大多数分词器不会创建跨越词边界的 token
视觉 token 的「token 空间」要大得多它是高维浮点数向量,每个维度都可以取很多值所以视觉 token 能传达更多的 bits per token这才是压缩的关键
另一个人补充文本 token 是子词单元视觉 token 在语义空间语义空间显然比子词切片压缩得多

免责声明:我不懂
还有人从视觉角度解释人类就是通过视觉看文本的所以文本必须有适应视觉噪声的机制看起来相似的词不能出现在相似的上下文否则会混淆
挺有意思的文本为了适应视觉识别反而在编码上有些”冗余”而视觉 token 直接在语义空间工作可以更高效所以 10 倍的压缩比
从信息论角度看其实挺合理的DeepSeek-OCR 做的事情是把这个直觉量化了用实验数据证明:一图确实胜千言
当然,我并不是这个领域的,评价不到正确与否,有懂的兄弟,还请评论区指导
怎么做到的
DeepSeek 这个东西的核心是一个叫 DeepEncoder 的架构380M 参数
这东西的设计很讲究它由三部分组成80M 的 SAM-base + 16 倍的卷积压缩器 + 300M 的 CLIP-large
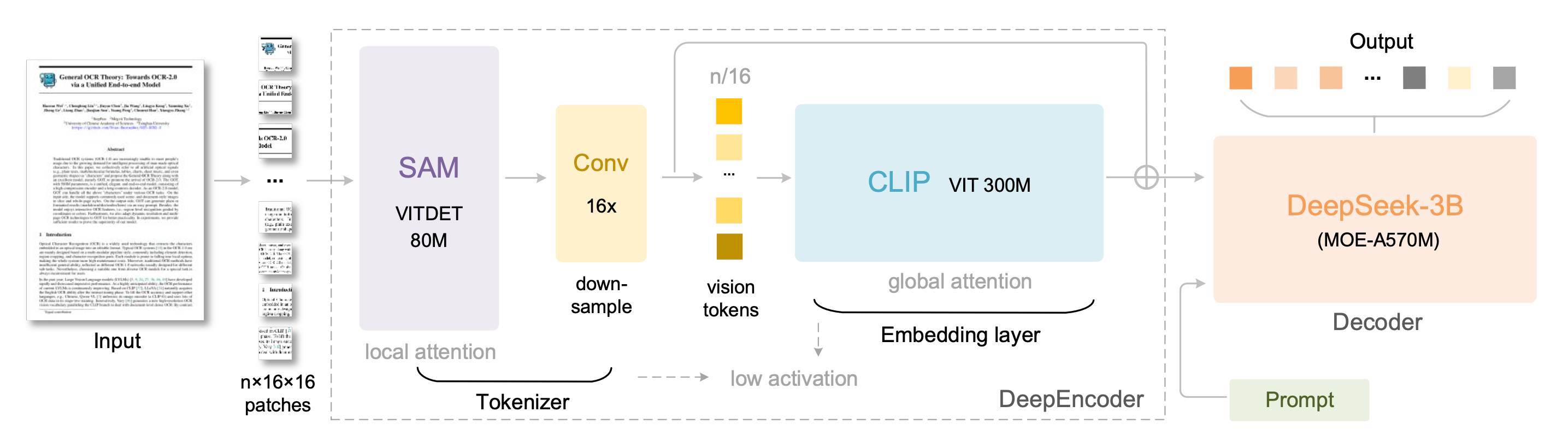
DeepEncoder架构流程图
这个设计有两个关键
第一个关键是「低激活」大部分 VLM 的视觉编码器激活值特别大InternVL2-76B 的激活参数是 76BQwen2.5-VL-72B 的激活参数是 72BDeepSeek-OCR 的解码器虽然是 3B 参数但激活参数只有 570M因为它用了 MoE 架构每次只激活一部分专家这意味着推理时显存占用小、速度快
第二个关键是「多分辨率统一」它设计了 6 种模式从 Tiny 模式的 64 个 token到 Gundam 模式的 800+ 个 token你可以根据文档复杂度选择幻灯片用 Tiny 就够了报纸得用 Gundam
另外值得一提的是DeepSeek-OCR 不只能识别文字还能「深度解析」文档里的图表、几何图形、化学式论文里叫这个能力 OCR 2.0比如金融报告里的图表它能直接转成结构化数据化学文档里的结构式它能转成 SMILES 格式

化学结构,也不在话下
这对金融、科研、教育领域太关键了
最有想象力的部分
论文最后有个很酷的设想
用降低图像分辨率来模拟人类的记忆遗忘
这个类比特别有意思人类记忆有个特点越久远的事情,记得越模糊刚发生的事,记得清清楚楚
一小时前的事,还很清晰一天前的事,开始模糊一周前的事,已经很模糊一年前的事,几乎忘光了
视觉感知也是这样10cm 的东西看得清清楚楚20m 的东西几乎看不清DeepSeek-OCR 提出可以用分辨率来模拟这种衰减
DeepSeek-OCR 提出了一个对应关系他们把不同的分辨率模式对应到人类记忆和视觉感知的清晰度等级这个类比是这样的
- 一小时前的事,还很清晰,对应Gundam模式(800+tokens)
- 一周前的事,已经很模糊,对应Base模式(256tokens)
- 一年前的事,几乎忘光了,对应Tiny模式(64tokens)
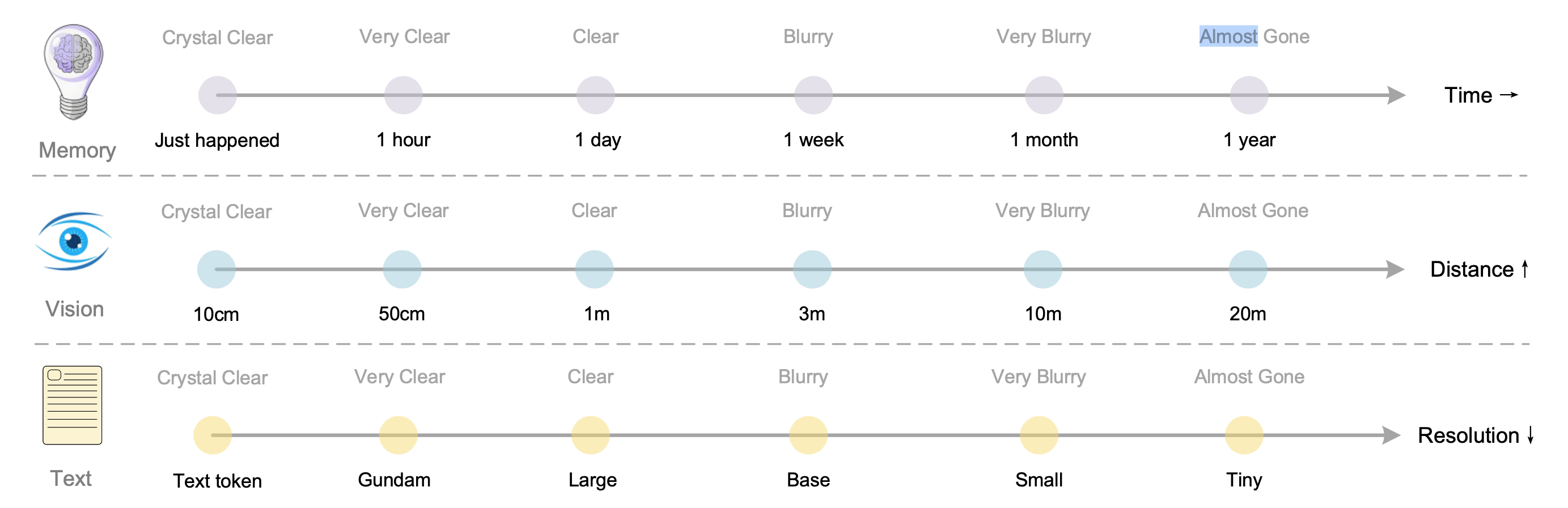
记忆遗忘机制:时间维度、距离维度、分辨率维度
最近的对话用高分辨率更早的对话逐渐降低分辨率这样既保留了历史信息又控制了 token 数量远期记忆自然「淡化」就像人类遗忘一样
这个设想论文里说还是早期阶段但想象空间很大如果真的能做到就能实现「理论上无限的 context window」
因为你不需要保持所有信息的高保真度只需要让信息随时间衰减就像人类记忆一样
开源和局限
整个项目采用 MIT 许可证开源代码、模型权重、技术论文全部公开
GitHub:
github.com/deepseek-ai/DeepSeek-OCR
Hugging Face:
huggingface.co/deepseek-ai/DeepSeek-OCR
说回来这个模型也有局限它不是聊天机器人因为没有 SFT 阶段某些能力需要用特定的 prompt 才能激活
超过 10 倍的压缩准确率会明显下降记忆遗忘机制还只是设想真正验证它在长上下文场景的效果需要更多实验
但即使有这些局限DeepSeek-OCR 已经证明了一件事视觉-文本压缩这条路是走得通的
最后
DeepSeek-OCR 最有价值的地方不在于它是一个好用的 OCR 工具而在于它用数据验证了一个假设视觉 token 确实可以更高效地表达信息
现在所有的 VLM 都是几千个 token 起步推理慢、显存占用大、长文档处理困难如果能把视觉 token 压缩 10 倍还几乎无损整个多模态系统的效率都能提升一个量级
记忆遗忘机制的设想也很有意思人类会遗忘不是因为大脑容量不够而是因为遗忘本身是一种优化策略
你不需要记住所有细节只需要记住重要的、近期的信息如果这条路真的走通了可能会改变我们对长上下文问题的理解不是无限扩大 context window而是让信息自然衰减就像人类记忆一样
回到开头 OpenAI 朋友的那个问题文字,是信息压缩的最好方式吗?DeepSeek-OCR 用数据给出了答案
而且,它是开源的任何人都可以用、可以改进、可以基于它做研究
作者【赛博禅心】,微信公众号:【赛博禅心】