本文将带你深入了解阿里最新发布的Qwen3-Omni模型,这是一个能够像人类一样全方位感知世界的全模态AI。从文本、图像、音频到视频,Qwen3-Omni不仅能够处理多种模态的信息,还能以极高的效率和智能进行交互。

大家好,我是冷逸。
人在杭州云栖大会现场,今年的主题叫「云智一体·碳硅共生」。
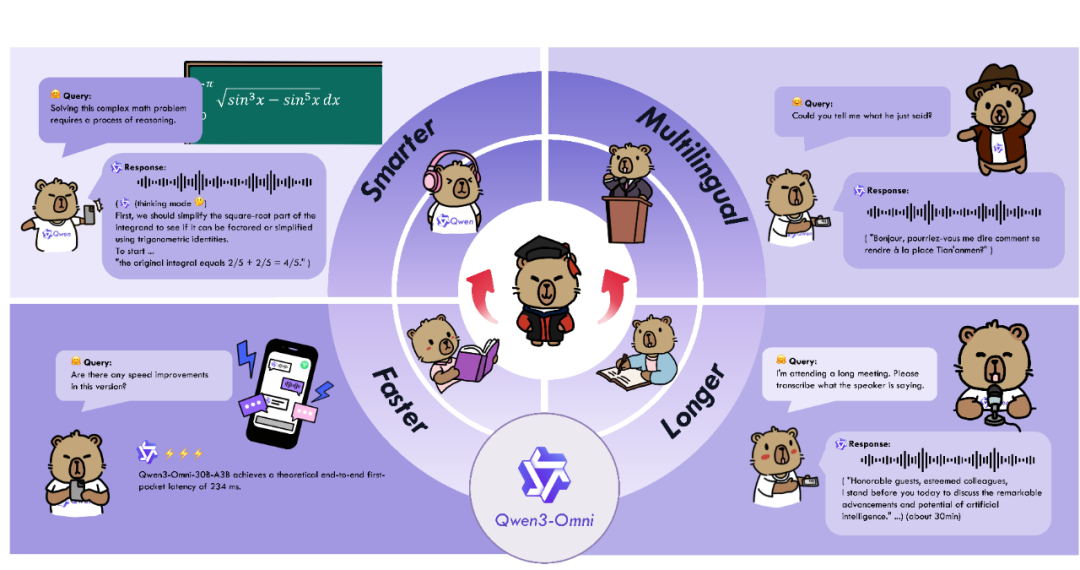
说到“碳硅共生”,Omni全模态是绕不开的难题。它要求,人工智能需要像人一样,自适应文本、图像、音频和视频等多模态信息的输入,来立体式感知我们的世界。
半年前,阿里发布了一款Qwen2.5-Omni模型,当时只有7B,已经很能打。
最近,他们又迭代了一版——Qwen3-omni,从预训练开始就是全模态混合训练,端到端原生支持全模态,就像人类婴儿一样,从出生就能全方位感知世界。
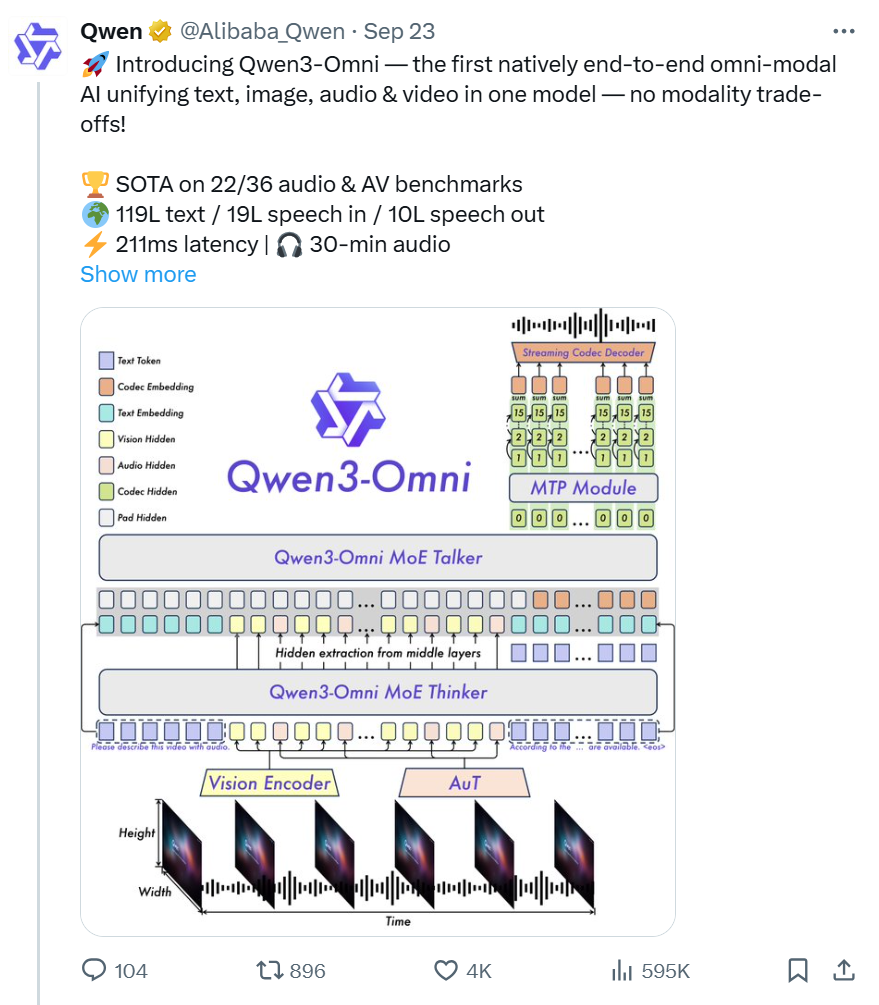
这是模型的性能评分。
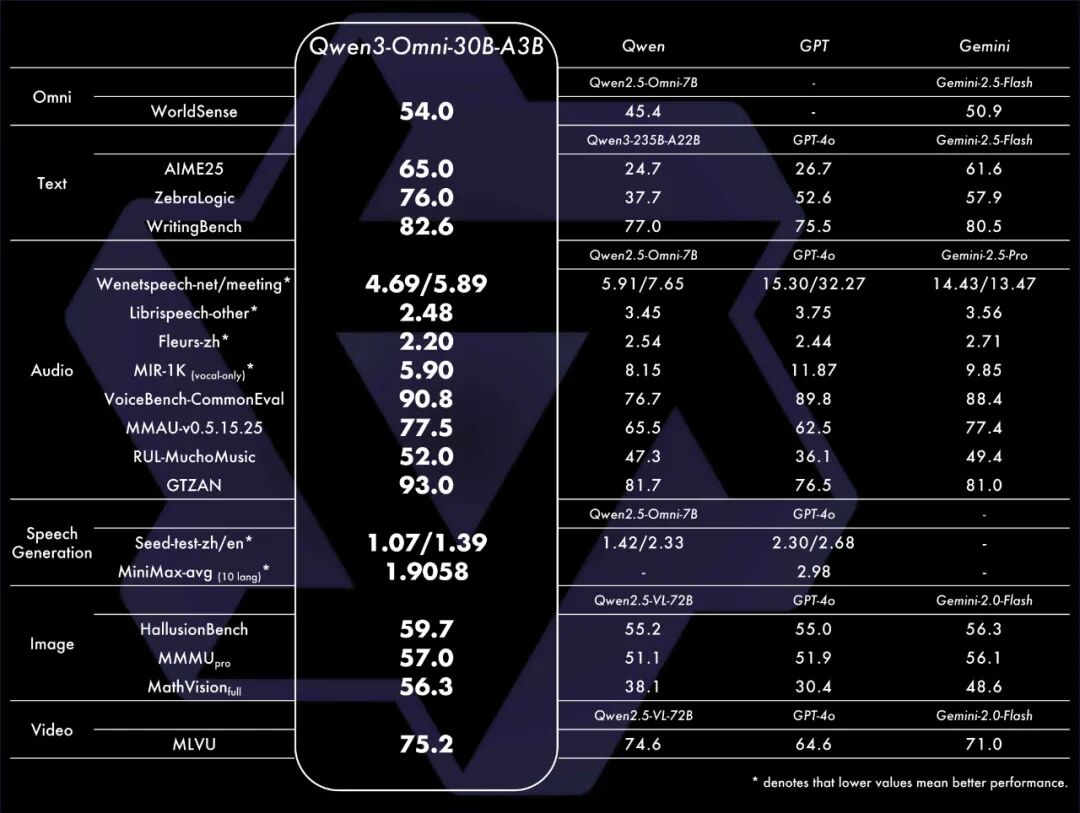
无论是综合性能(WorldSense),还是文本、音频、图像、视频以及音频合成等多模态任务,相比上一代都有大幅提升,对比GPT-4o、Gemini-2.5-Flash也是全面超越。
简单来说就是,脑子更好使了,速度还更快了,支持语言也更多了。
当然,更NB的是,这个模型依旧继续开源,而且还是采用自由度最高的Apache 2.0协议开源,所有人都可以免费商用。
今天,HuggingFace趋势榜快被Qwen包圆了
以下,是一些部署渠道。
模型下载(HF):
https://huggingface.co/collections/Qwen/qwen3-omni-68d100a86cd0906843ceccbe
模型下载(魔搭):
https://modelscope.cn/collections/Qwen3-Omni-867aef131e7d4f
API调用:
https://bailian.console.aliyun.com
Demo地址:
https://modelscope.cn/studios/Qwen/Qwen3-Omni-Demo
如果想直接上手体验,也可以在「Qwen Chat」网页或APP中体验。
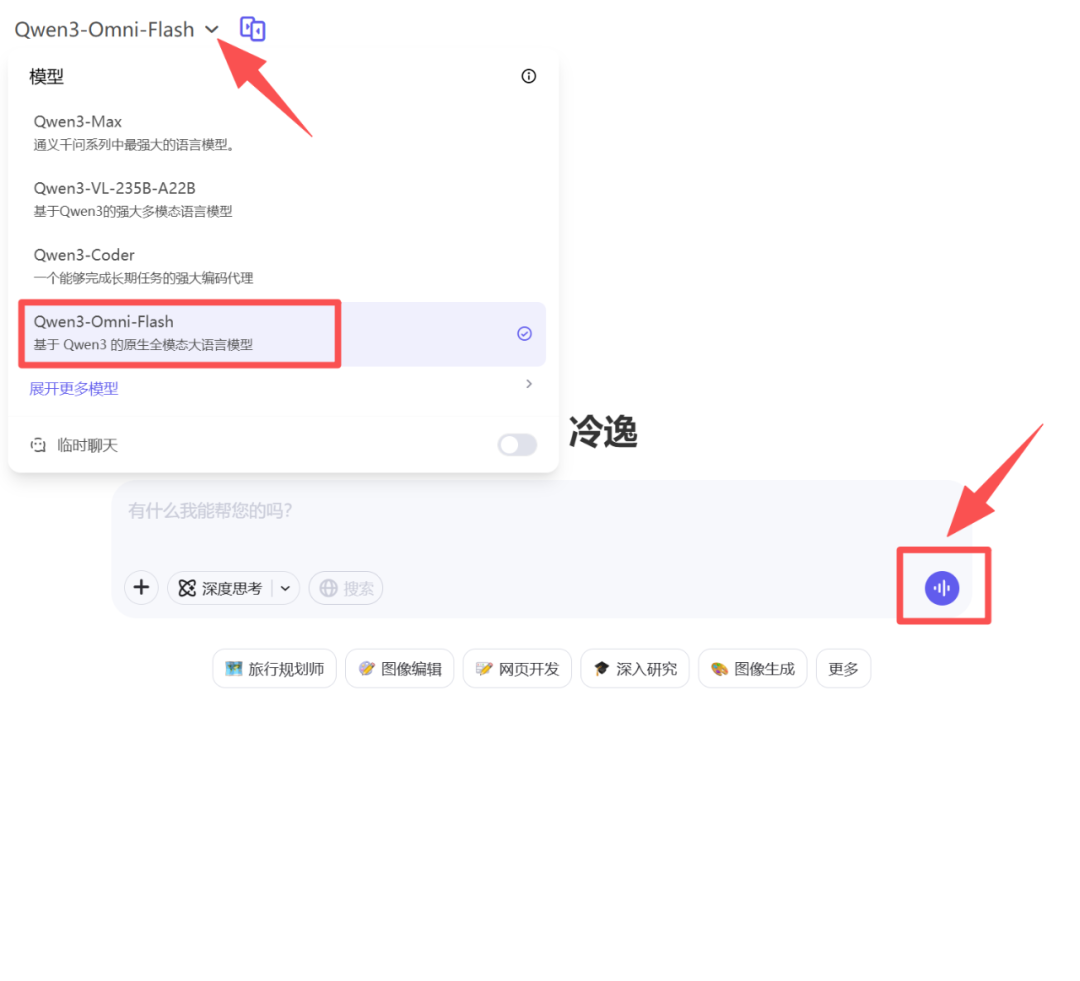
体验地址:https://chat.qwen.ai
在手机/电脑上,选择模型“Qwen3-Omni-Flash”,点那个声波图标,就可以体验了。
实测体验
因为是原生全模态基础模型,所以Qwen3-Omni的可玩度非常丰富。
1)跨语言交互
Qwen3-Omni支持119种文本语言交互、19种语音理解语言和10种语音生成语言。
比如,用中文提问,展示中英双语菜单,然后让模型用法语给朋友推荐一道菜。这个case极其考验模型的跨语言交互能力,Qwen3-Omni处理得非常丝滑。
以后,出国旅游带上它,就够了。
2)个性化人设
Qwen3-Omni支持system prompt任意定制,可以自由设置你的回复风格、人设等。
比如,一位讲广东话的幼儿教师、四川女汉子……
哈哈,这四川女汉子有那味了。
3)长音频支持
Qwen3-Omni最长支持30分钟音频/3分钟视频的理解,有了它开会不愁。
4)音视频推理
模型的推理能力也很强。
拿来做题、扫街、展览指引、车载控制(需集成外部工具/服务),都非常的合适。
5)音乐分析
因为原生全模态预训练,Qwen3-Omni是能听懂纯音乐的。
6)多人互动
在官方case中,我觉得最有意思的是这个。
大家故意一通“瞎搅和”的输入,模型依然能清晰记住整个信息,精准定位和提取需要的信息,包括人说话的内容、情绪,它都记得。
这颇有点Jarvis的味道了。
7)更多实测
模型上线「Qwen chat」后,我自己也做了一些实测。
比如,我们早餐不知道吃什么,焦虑哪道菜的卡路里更高,我就直接问它。
前几天,朋友@一泽 设计的AI梗图很有意思,这是其中一张,考考Qwen3-Omni。

回答正确,画蛇添足,而且还能提供英文解读。
上周末,比亚迪仰望U9X跑出496.22km/s的极速,成为全球最快汽车。仰望研究院院长杨峰接受媒体专访,这个视频我是真想看,但是时长达1个多小时。
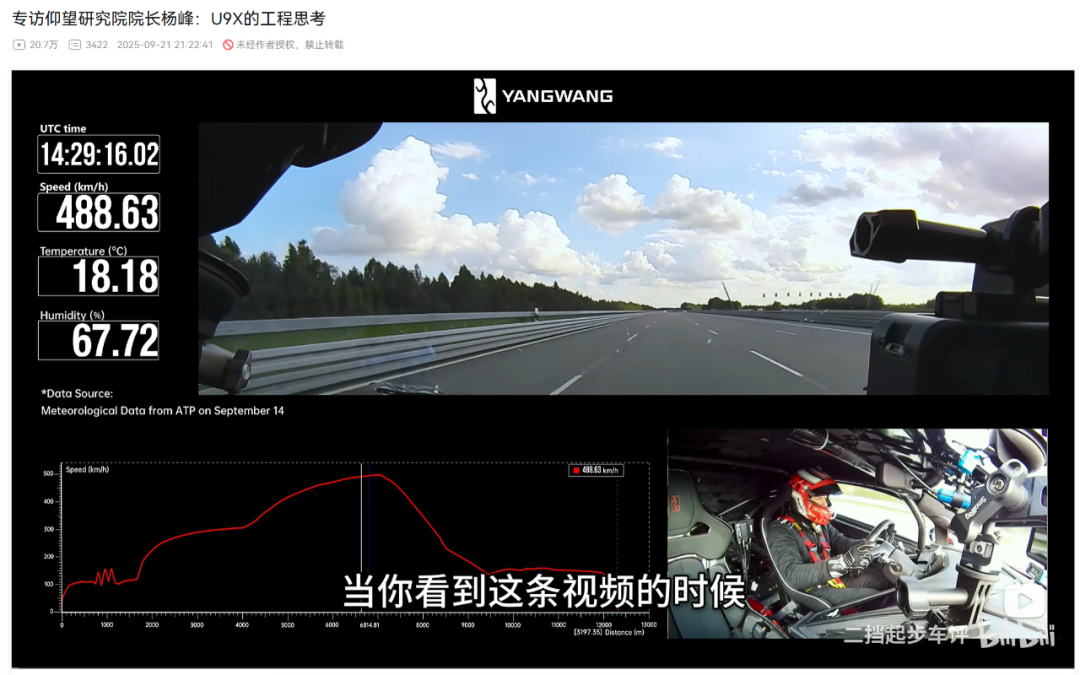
我们丢给Qwen3-Omni试试。
在魔搭里找到Qwen3-Omni-Demo,输入提示词,开始录制音频。
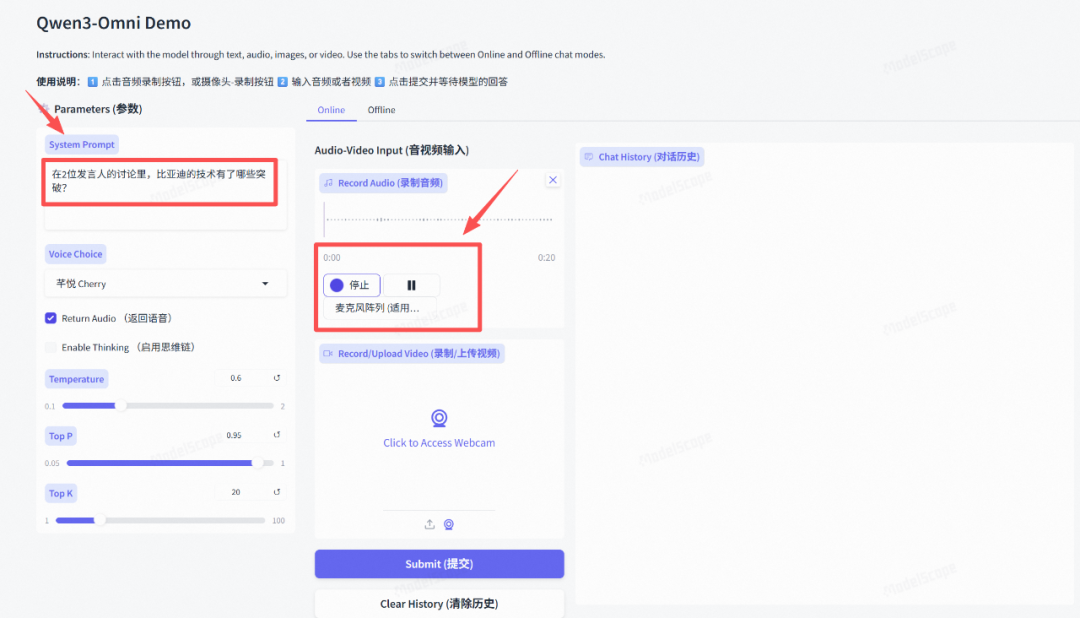
体验链接:
https://modelscope.cn/studios/Qwen/Qwen3-Omni-Demo/
Qwen3-Omni最长可以支持30分钟,我先录制6分钟试试效果。没想到,总结得还挺全面的。
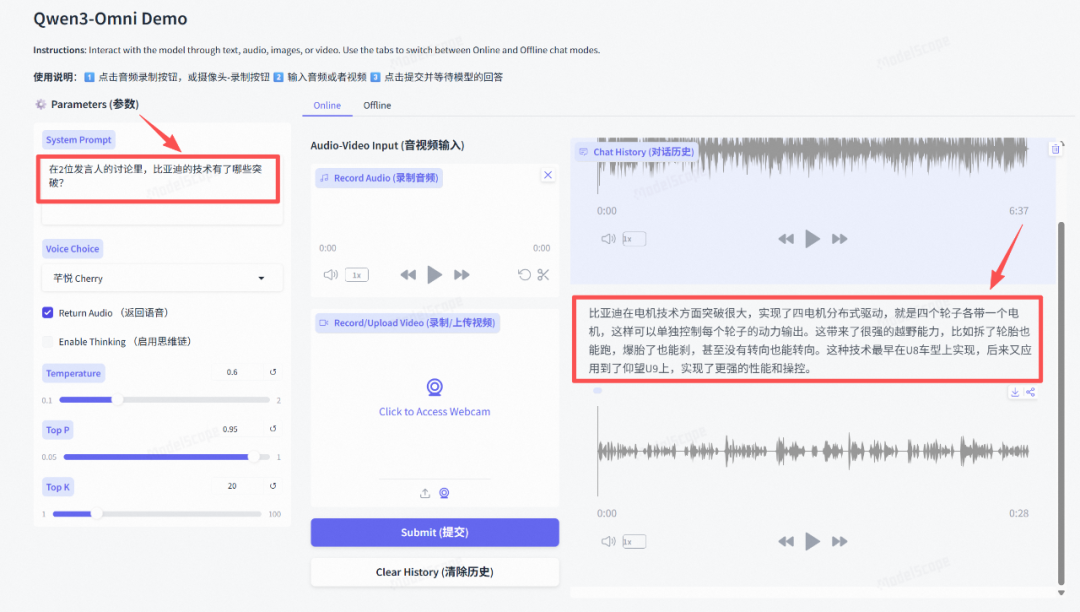
也会同步生成一份音频。
从官方case+我自己实测case来看,这个模型的智力表现还是挺强的,百科知识的储备非常全面,在模态全面拓展的同时一点都不丢智力表现。而且反应也很快,延迟特别低(基本上都不到2s)。
相比上一代Qwen2.5-Omni,Qwen3-Omni的进步实在太大了。
技术解读
那这是怎么做到的,官方介绍:
「Qwen3-Omni采用的是Thinker-Talker架构,Thinker负责文本生成,Talker专注于流式语音Token生成,直接接收来自Thinker的高层语义表征。为实现超低延迟流式生成,Talker通过自回归方式预测多码本序列:在每一步解码中,MTP模块输出当前帧的残差码本,随后Code2Wav合成对应波形,实现逐帧流式生成。」
说人话就是,Qwen3-Omni就像两个人合作:一个负责思考要说什么(Thinker),另一个负责把思考的内容立刻说出来(Talker),这样就能实现超低延迟的语音生成。
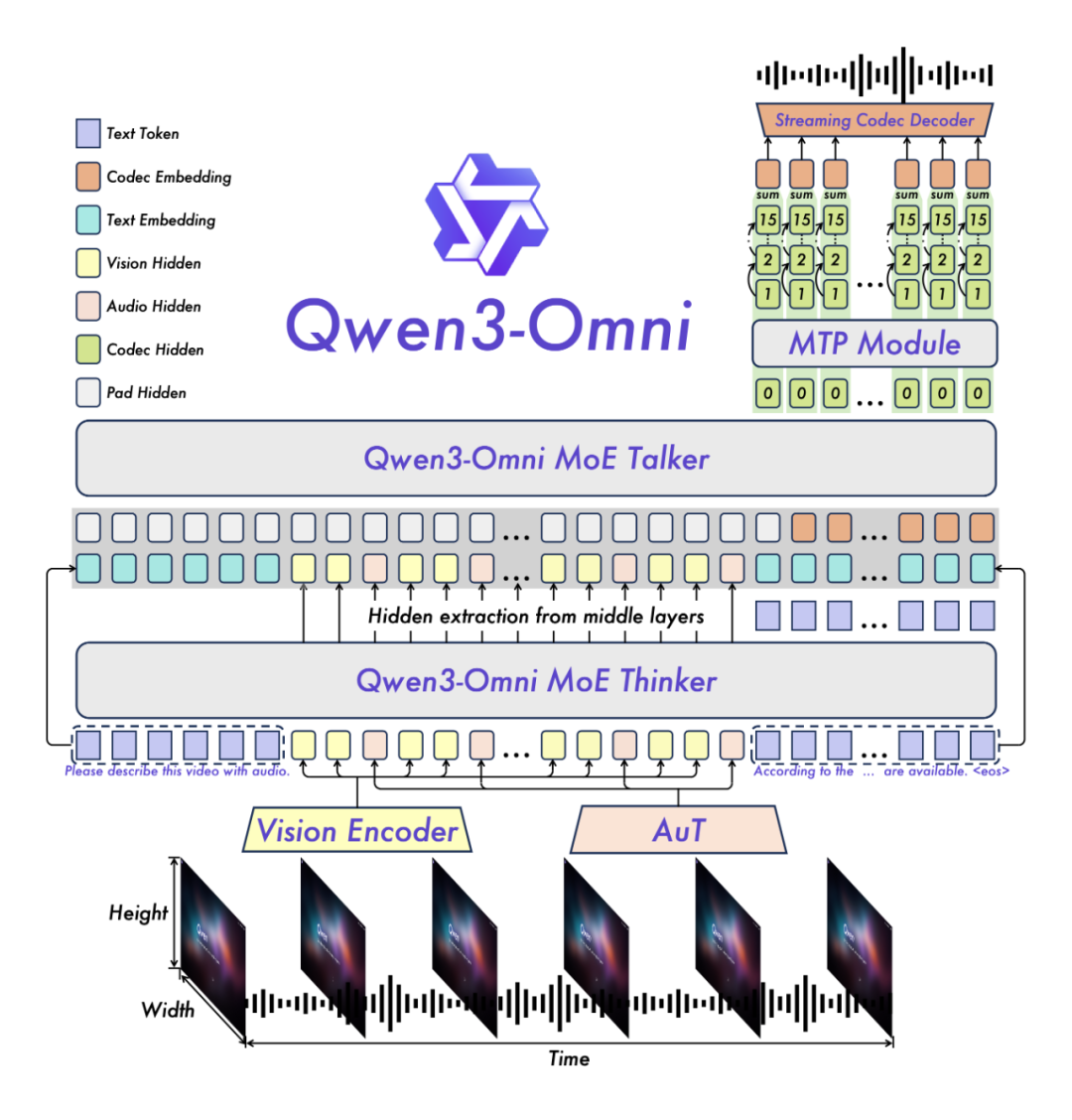
创新架构设计
- AuT:音频编码器采用基于2000万小时音频数据训练的AuT模型,具备极强的通用音频表征能力。
- MoE:Thinker与Talker均采用MoE架构,支持高并发与快速推理。
- 多码本技术:Talker采用多码本自回归方案——每步生成一个编解码帧,MTP模块同步输出剩余残差码本。
全模态不降智
在文本预训练早期混合单模态与跨模态数据,可实现各模态混训性能相比纯单模态训练性能不下降,同时显著增强跨模态能力。
卓越的语音对话与指令跟随能力
Qwen3-Omni在语音识别与指令跟随任务中达到Gemini-2.5-Pro相同水平。
实时音频和音视频交互
AuT,Thinker, Talker + Code2wav全流程全流式,支持首帧token直接流式解码为音频输出。
如果是自部署,这是最低GPU要求。

写在最后
人有六根,眼耳鼻舌身意。
现在的AI也快“成人”了,Qwen3-omni能听、能看、能说、能记忆还能思考,就差一具躯壳了。
阿里Qwen在Omni全模态领域持续进化,给我们带来更新更快的先进模型,无论是盲人辅助、智能硬件、智能家居、手机延伸还是具身智能,都可以借助这个模型打造专属的智能应用。
比如,出国用它翻译菜单、理解交通,家长用它辅导作业,逛街用它扫货、了解品牌故事,给公仔接入API让它开口说话,好声音可以请它当导师,三缺一找它打麻将……嗯,我还真想试试让Qwen3-omni打麻将,下期选题安排!
这代表着AI与人的交互进入了一个新的维度——AI越来越像人,也越来越全能。
感谢阿里!
感谢Qwen!
因为你们的持续开源,我们离ASI(超级人工智能)又近了一步。
作者【沃垠AI】,微信公众号:【沃垠AI】