OCR技术的演进,正在从“识别能力”走向“压缩效率”。本文深度解析DeepSeek-OCR如何通过上下文光学压缩实现SOTA级性能,以更少的视觉Token完成更精准的识别任务,重塑AI文档解析的工程范式,为产品人和技术团队提供一套可部署、可扩展的智能入口。
今天,DeepSeek开源了最新的模型:DeepSeek-OCR。
省流:模型仅3B,单张A100-40G卡每天可跑20万页的LLM/VLM训练数据。
更详细来说:DeepSeek提出了一种新的研究——上下文光学压缩,并通过DeepSeek-OCR模型验证了可行性。实验显示,当文本token数量不超过视觉token的10倍(压缩比低于10×)时,模型的OCR精度可达97%;即便压缩比提高到20×,准确率仍保持约60%。
小学生的理解就是,压得轻一点,它几乎全认对;压得狠一点,也能认得七七八八。
在专门的文档解析评测基准OmniDocBench上,DeepSeek-OCR只使用100个视觉Token就超越了GOT‑OCR2.0(每页256个Token), 并在使用不到800个视觉Token的情况下优于MinerU2.0(平均每页6000+个Token)。
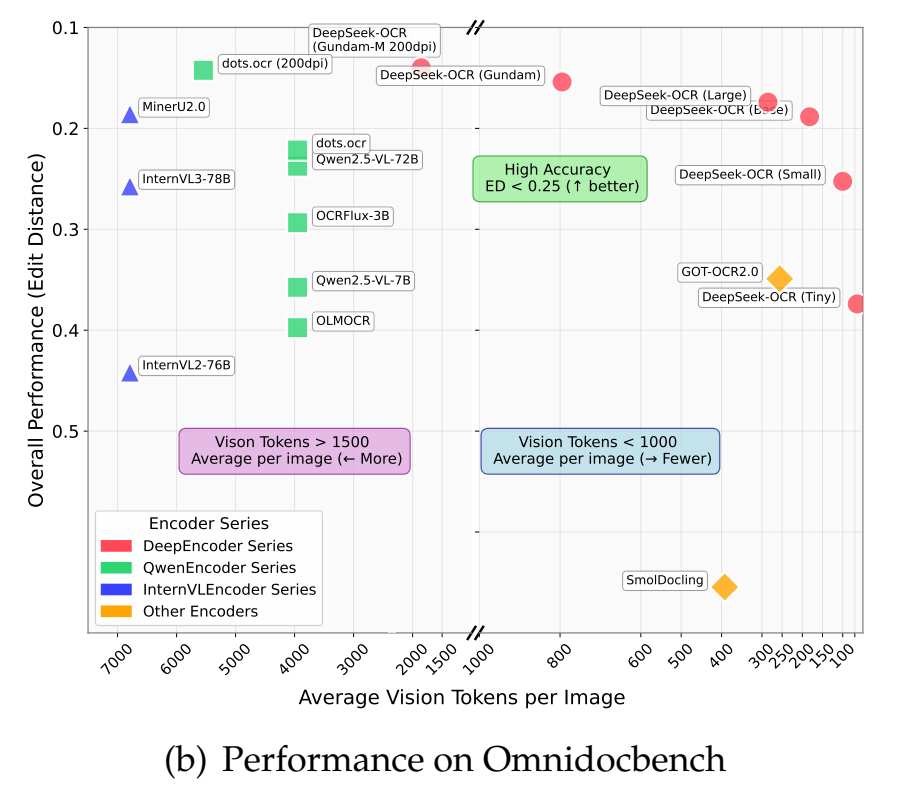
比其他模型更省token,精度还更高。
这个模型,有着超高的实用价值。
先看示例
下面几则示例,均来自DeepSeek技术论文里的case。
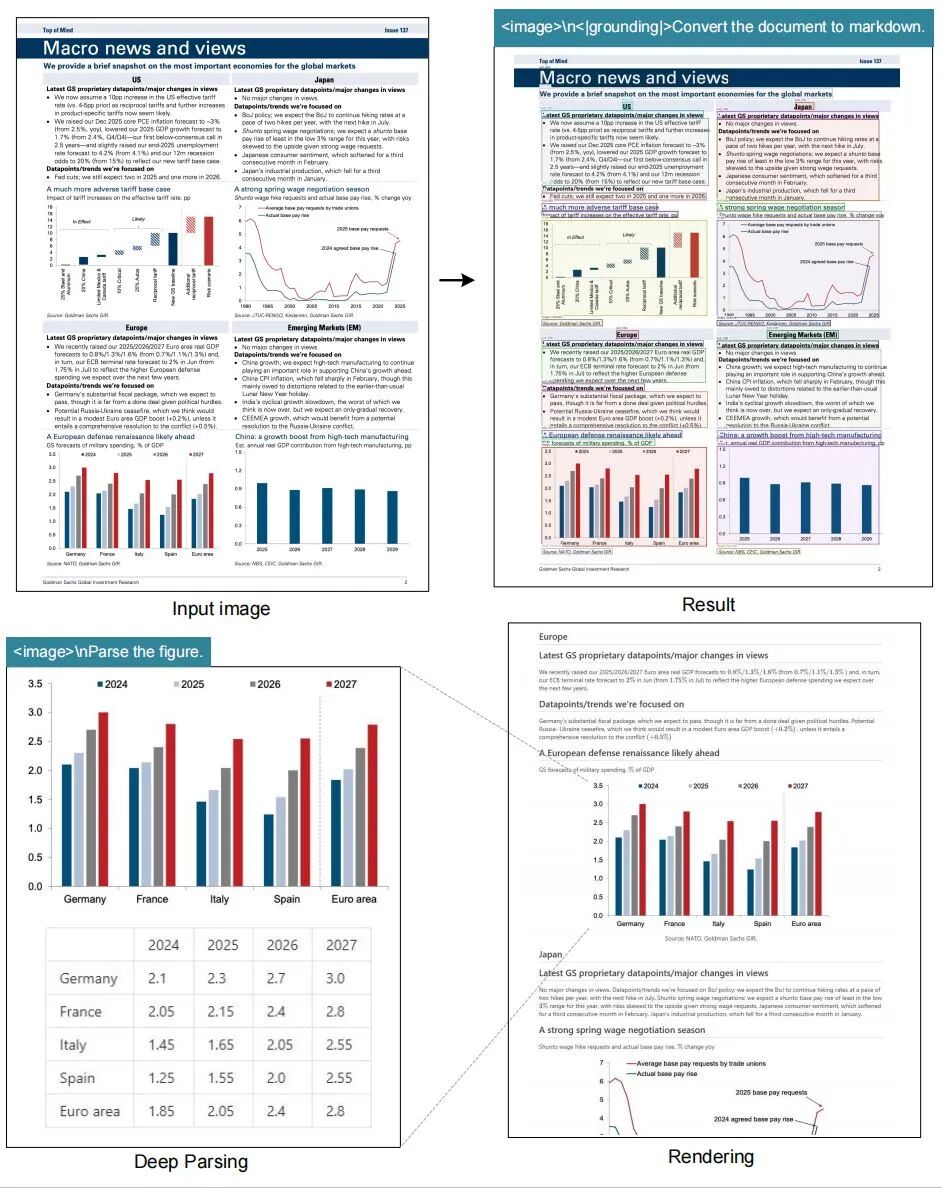
比如,这是某电子书的一页。原图片,是比较糊的。

模型先进行markdown识别,把整页文字大概识别出来。

这个过程中,必然会有字母丢失或识别不准的情况。然后,模型启动深度的语法解析过程,自动推理、纠错。

最后,得到了一个更精准的结果。

整个工作过程,长这样。

可以识别作业题,包括几何图形也能识别。

带各种数据图表的金融研究报告,也能准确识别。
也包括一些来自现实生活中的图片,无论拍摄角度、字形、字体发生什么变化,都能精准识别。

对于PDF文档,DeepSeek‑OCR可以处理近100种语言,支持布局和非布局OCR格式。


区别于其他OCR模型,DeepSeek‑OCR还具备“深度解析”的能力。
通过二次模型调用(需要配备提示词),可以对图表、几何图形、化学公式以及现实中的图片进行深度解析、推理。
更多场景
OCR模型,可以把“死图片”秒变“活数据”,让机器和人都能直接“抄对作业”。
比如:
- 纸质档案电子化。政府、银行、医院堆成山的纸质卷宗,OCR一跑就能生成可搜索、可复制的企业知识库,检索1秒vs人工翻10分钟。
- 实时证件识别。机场、酒店、网吧刷身份证/护照,OCR1秒读出姓名、号码、有效期,自动填表+公安联网核验,排队时间砍半。
- 法律/知识产权检索。判决书、专利说明书OCR后全所可搜,律师输入“先履行抗辩权”秒级定位5年内的相关案例,准备材料时间从3天缩到1小时。
- 风控打假。合同、回执、仓单、车牌、集装箱号,OCR秒抽关键字段,与系统比对,发现伪造/篡改立刻报警,金融、港口、二手车平台靠它堵漏洞,一年少亏几千万。
- 无障碍阅读。盲人用手机扫书,OCR把文字读出来;视障者“听”邮件、“听”药品说明书,信息差直接抹平。
企业生产场景中,几乎没有哪个场景不与OCR打交道。
优秀OCR=省人力、降差错、提速度、挖数据,把“死图片”变成“任何系统都能直接使用的活数据”,是数字化流程的第一闸口,也是AI落地的“现金牛”场景。
怎么部署
因为是开源的,所以任何企业都可以进行部署。
在github上,DeepSeek提供了快速部署指引。
1)安装
前提:确保环境是cuda11.8+torch2.6.0。
1.1 克隆此仓库并定位到 DeepSeek-OCR 文件夹。git clone https://github.com/deepseek-ai/DeepSeek-OCR.git
1.2 Condaconda create -n deepseek-ocr python=3.12.9 -yconda activate deepseek-ocr
1.3 下载 vllm-0.8.5 pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 –index-urlhttps://download.pytorch.org/whl/cu118pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whlpip install -r requirements.txtpip install flash-attn==2.7.3 –no-build-isolation
2)vLLM推理
前提:更改 DeepSeek-OCR-master/DeepSeek-OCR-vllm/config.py 中的 INPUT_PATH/OUTPUT_PATH 和其他设置。
2.1 mage: streaming outputpython run_dpsk_ocr_image.py
2.2 pdf: concurrency ~2500tokens/s(an A100-40G)python run_dpsk_ocr_pdf.py
2.3 batch eval for benchmarkspython run_dpsk_ocr_eval_batch.py
3)Transformers推理
Transformersfrom transformers import AutoModel, AutoTokenizerimport torchimport osos.environ[“CUDA_VISIBLE_DEVICES”] = ‘0’model_name = ‘deepseek-ai/DeepSeek-OCR’tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)model = AutoModel.from_pretrained(model_name, _attn_implementation=’flash_attention_2’, trust_remote_code=True, use_safetensors=True)model = model.eval().cuda().to(torch.bfloat16)# prompt = “nFree OCR. “prompt = “n<|grounding|>Convert the document to markdown. “image_file = ‘your_image.jpg’output_path = ‘your/output/dir’res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 640, crop_mode=True, save_results = True, test_compress = True)
或者,你也可以cd DeepSeek-OCR-master/DeepSeek-OCR-hfpython run_dpsk_ocr.py
目前,开源模型支持以下模式:
原生分辨率:
- Tiny:512×512(64visiontokens)
- Small:640×640(100visiontokens)
- Base:1024×1024(256visiontokens)
- Large:1280×1280(400visiontokens)
动态分辨率:
Gundam: n×640×640 + 1×1024×1024
4)提示词示例:
# document: n<|grounding|>Convert the document to markdown.# other image: n<|grounding|>OCR this image.# without layouts: nFree OCR.# figures in document: nParse the figure.# general: nDescribe this image in detail.# rec: nLocate <|ref|>xxxx<|/ref|> in the image.# ‘先天下之忧而忧’
更多开源信息,可参考:
github:
https://github.com/deepseek-ai/DeepSeek-OCR
huggingface:
https://huggingface.co/deepseek-ai/DeepSeek-OCR写在最后
目前,业界OCR普遍有两大难题:一是精度问题,二是成本问题。
DeepSeek换了个思路,把文字“拍”成图,让视觉模型当压缩器:原来上千个文本token才能说完的话,现在几十个视觉token就装下,压缩率直接拉到10×以上。
这套“光学压缩”方案落地成DeepSeek-OCR,token用得最少,成绩却刷到SOTA:一页A4论文,100个视觉token就能原样吐回1000+文本token,精度97%。
算力直接打一折,成本跟着跳水。更绝的是,模型连权重一起开源,零门槛白嫖。
把贵的东西做成白菜价,还顺手把账本公开——这操作,很DeepSeek。
作者【沃垠AI】,微信公众号:【沃垠AI】